






Long Transactions in GIS
-
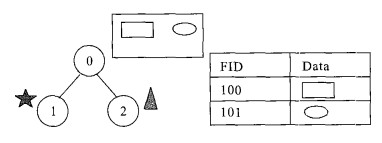
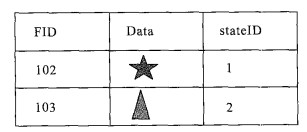
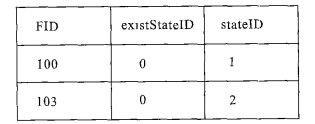
摘要: 为了解决传统的使用基于关系型数据库管理系统(relational database management system, RDBMS) 存储数据的GIS软件平台在需要长事务并发的应用过程中出现问题, 从GIS对长事务需求和一般对事务的处理方式遇到的问题入手, 将GIS数据的编辑过程归结为数据库状态的不断演变, 通过增加存储表格的手段, 提出了一套切实可行的长事务解决方案, 并给出了相关问题的算法说明.传统的并发是在编辑之前对要素加锁, 在这个编辑过程中, 其他用户都不能编辑这个要素, 直到第一个用户完成编辑, 释放锁, 其他用户才能对这个要素进行修改.这样存在2个问题: 多个用户不能同时编辑一个要素; 后面的用户对数据的修改会覆盖掉前面用户的编辑结果.为了解决这些问题, 本方案用状态标识数据的改变, 通过对状态的控制较好地解决了长事务的并发问题, 使多个用户不仅可以同时访问相同的要素, 而且不同的用户的编辑结果可以分别保存, 互不影响.该方案已应用到实践中, 取得了良好的效果.Abstract: This paper offers a solution to the application of a GIS system based on relational database management system (RDBMS) in a given circumstance which requires a long transaction. The traditional method to long transaction is to add locks on data in order to let someone edit it exclusively. That is to say, data can not be edited by more than one person at the same time with the traditional method. The paper starts from the requirement from GIS to long transaction and the questions which went on when people deal the long transaction with the traditional method. A feasible solution is offered which treats a data change as a statement and mark changes in data by state ids, then uses two algorithms to control the statements. With this solution not only data can be edited by few persons synchronously but also the different changes made by different people can be saved respectively.
-
Key words:
- GIS /
- long transaction /
- concurrency control
-
Abraham, S., Henry, E. K., Sudarshan, S., 2003. Database system concepts, fourth edition. Translated by Yang, D. Q., Tang, S. W. . China Machine Industry Press, Beijing (in Chinese). Garcia, M. H., Salem, K., 1987. Sagas. In: Francisco, S., ed. . Proceedings of the ACM SIGMDD conference. ACM Press, CA. 249 -259. Hector, G. M., Jeffrey, D. U., Jennifer, W., 2003. Database system: The complete book. Translated by Yue, L. H., Yang, D. Q., Gong, Y. C., et al. . China Machine Indus-try Press, Beijing (in Chinese). Wu, X. C., 2004. The new generation of MAPGIS. Geomatics World, 2 (2): 3 -7 (in Chinese with English abstract). Abraham, S., Henry, E. K., Sudarshan, S., 2003. 数据库系统概念. 杨冬青, 唐世渭, 译. 北京: 机械工业出版社. Hector, G. M., Jeffrey, D. U., Jennifer, W., 2003. 数据库系统全书. 岳丽华, 杨冬青, 龚育昌, 等, 译. 北京: 机械工业出版社. 吴信才, 2004. 新一代MAPGIS. 地理信息世界, 2 (2): 3 -7. -
 下载:
下载:
 点击查看大图
点击查看大图
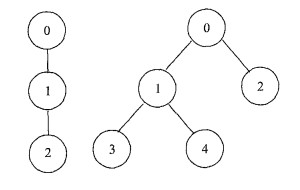
图(4)
计量
- 文章访问数: 3966
- HTML全文浏览量: 393
- PDF下载量: 8
- 被引次数: 0
