登录
登录 注册
注册 高级检索
高级检索 邮件订阅
邮件订阅 RSS
RSS



当期目录
 摘要
摘要 HTML全文
HTML全文 PDF 3985KB
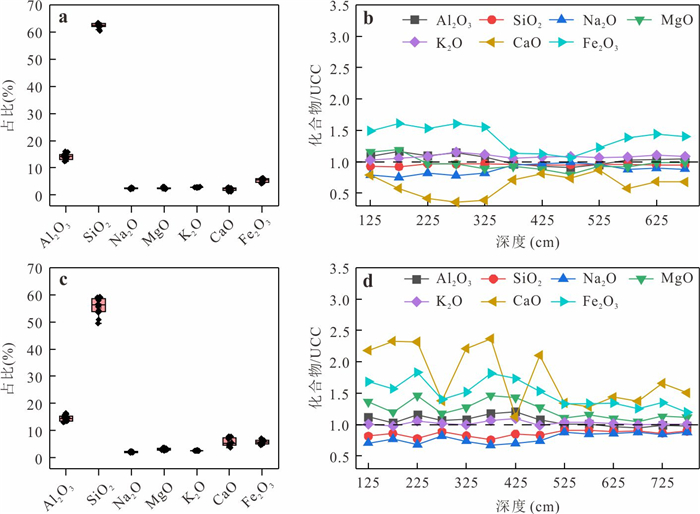
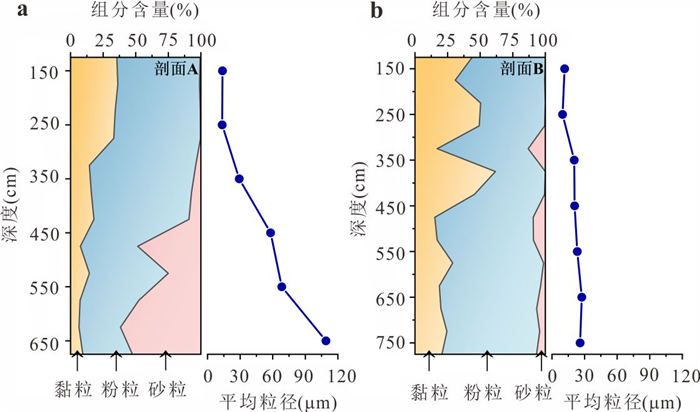
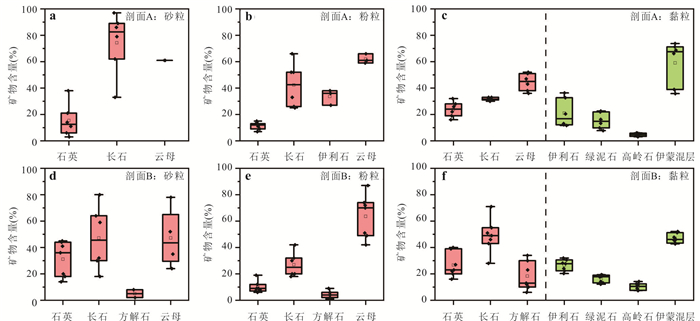
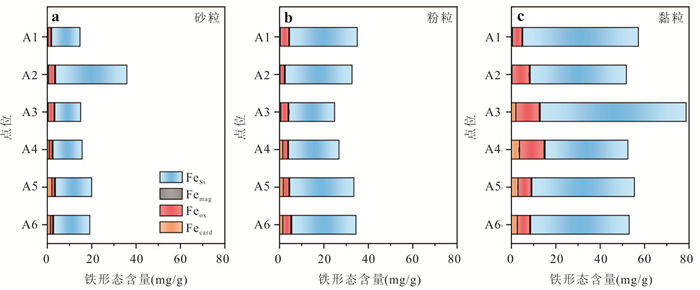
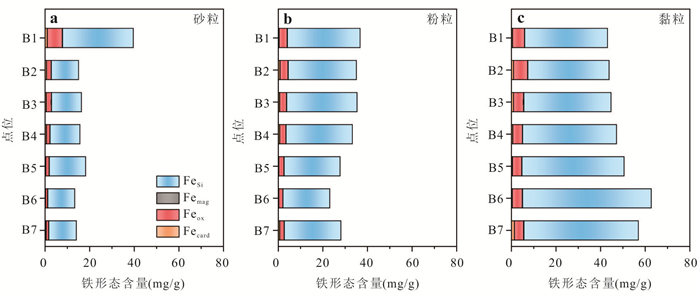
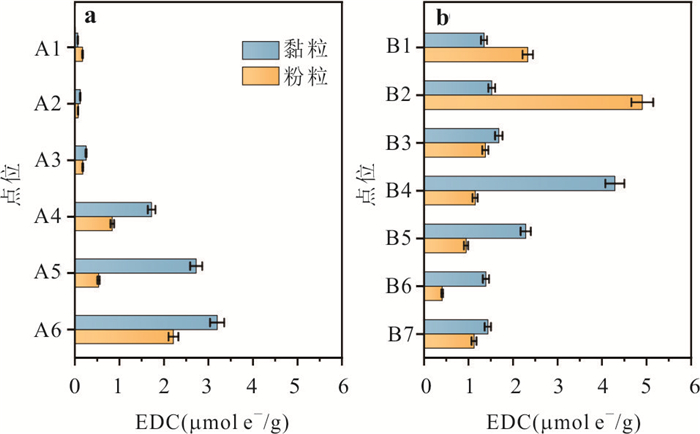
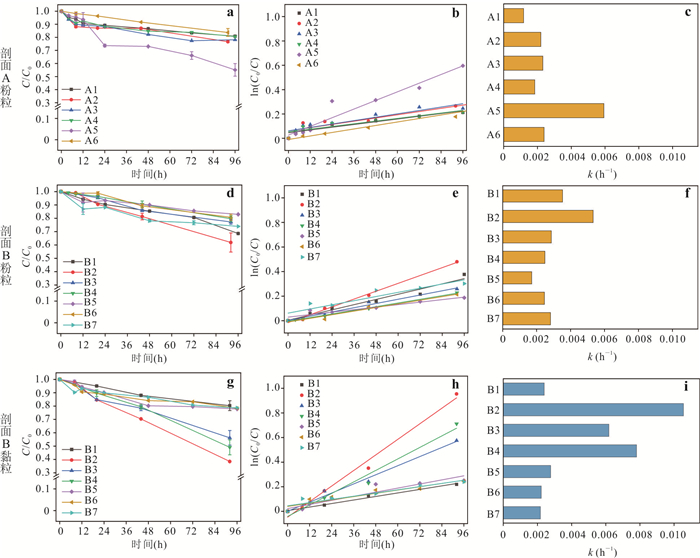
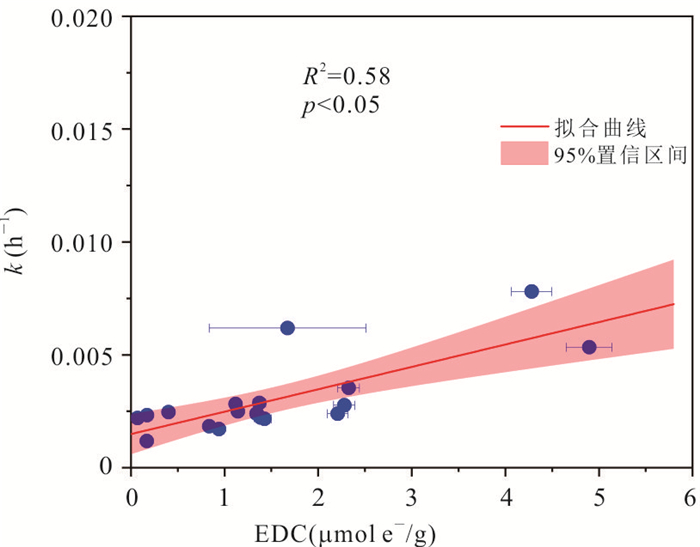
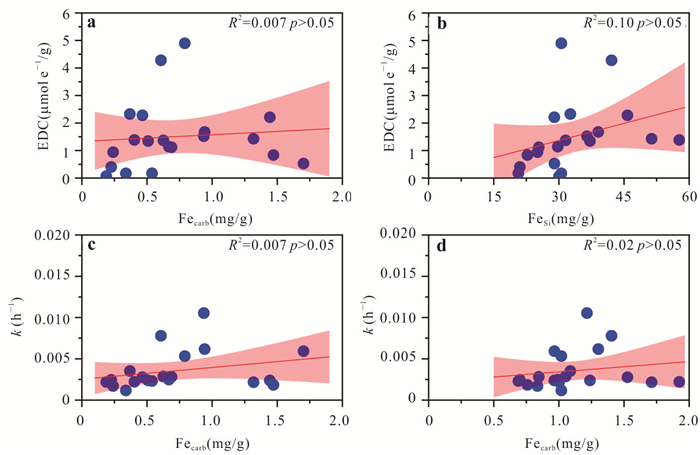
PDF 3985KB为了探究沉积物中矿物分布、还原能力以及非生物还原有机污染物速率之间的关系,选取了两组典型柱状沉积物样品,系统开展了沉积物常量元素与粒径组成、矿物分布及铁赋存状态等地球化学特征分析,定量表征了不同粒径沉积物的供电子能力(electron-donating capacity,EDC),探究了沉积物非生物还原硝基苯的动力学过程.结果表明:不同粒径沉积物中主要矿物不同,伊利石等活性黏土矿物主要富集在黏粒中;黏粒的EDC高于粉粒,且黏粒对硝基苯的非生物还原速率高于粉粒;EDC不仅可以定量表征沉积物的还原能力,而且可作为评估沉积物非生物还原硝基苯能力的指示参数,为预测含水层中硝基苯发生非生物还原的潜力提供理论依据.
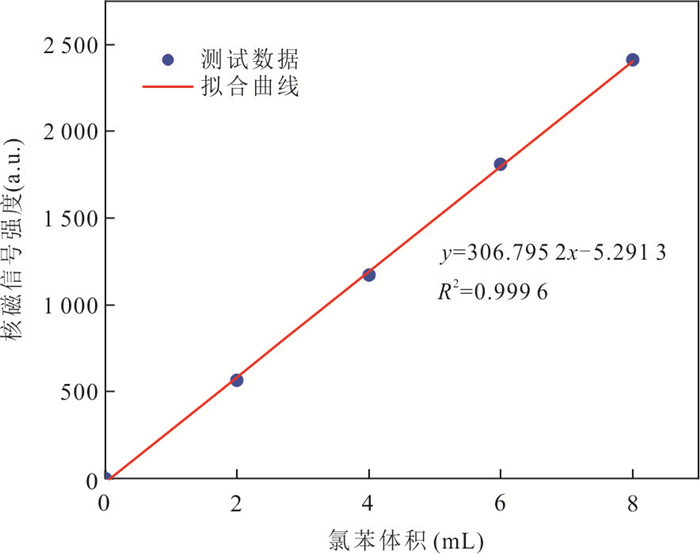
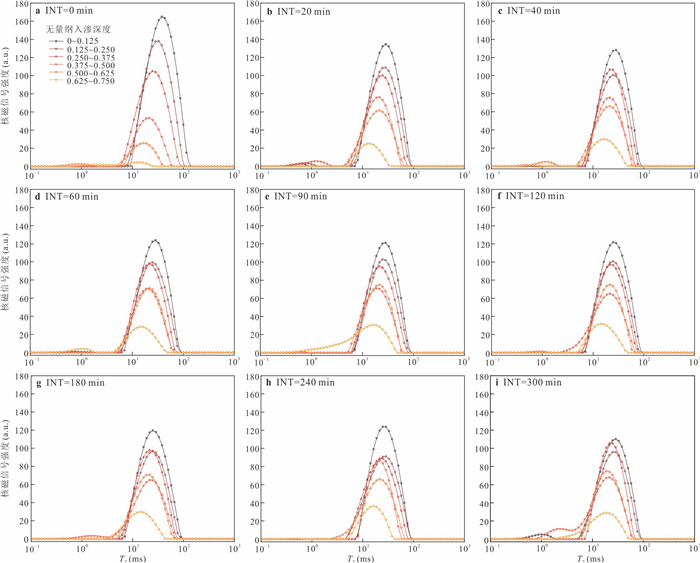
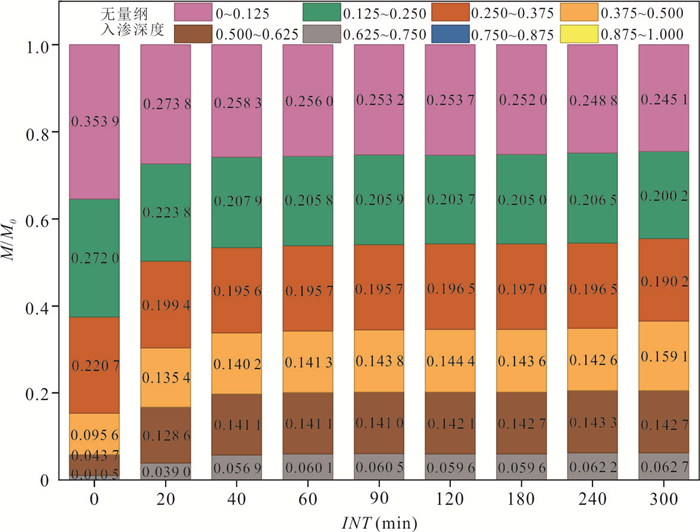
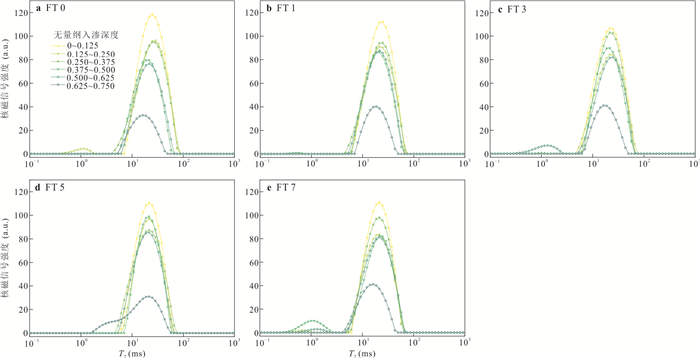
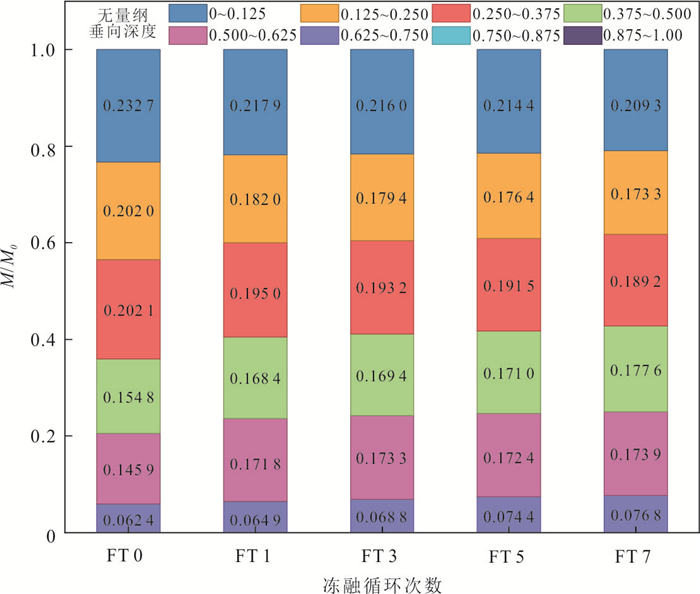
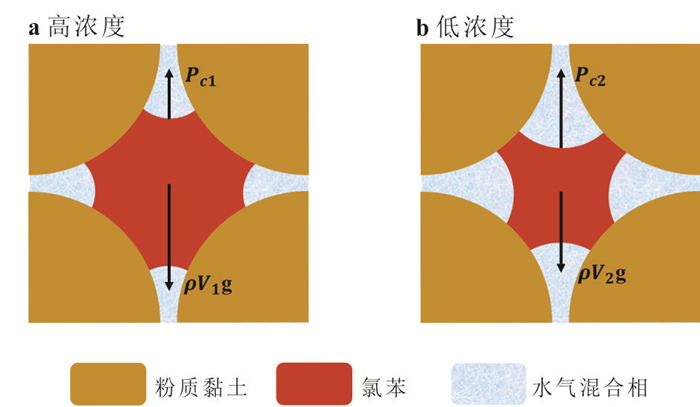
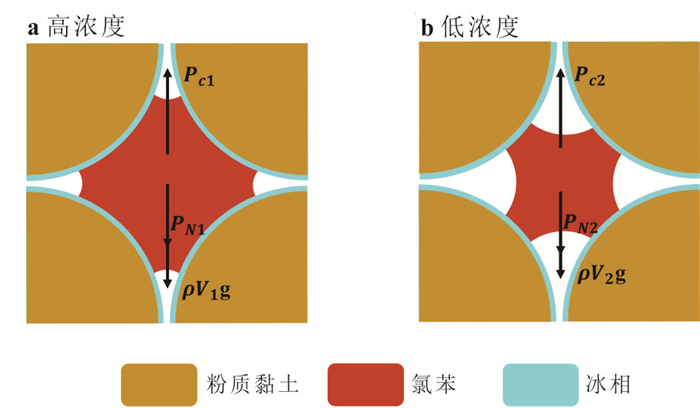
探明包气带重非水相液体(dense non-aqueous phase liquids, DNAPLs)自发入渗稳定后受冻融循环作用的再运移规律及机制对季节性冻融区污染场地修复至关重要.选取氯苯作为典型DNAPL,以西藏色季拉山口的粉质黏土为多孔介质,利用分层核磁共振技术定量测试不同入渗时间及冻融循环次数后在土柱垂向空间位置的氯苯含量.研究表明:随着入渗时间的增加,无量纲入渗深度0~0.375范围内氯苯浓度呈下降趋势,0.375~0.750范围内氯苯浓度呈上升趋势.冻结产生的冻结诱导压力驱动入渗稳定后的氯苯向下再运移,但驱动能力有限,不同冻融循环后氯苯浓度变化率最小的为3.51%,最大的不超过24%.自发入渗和冻融循环过程中,毛细力、重力和冻结诱导压力的相互作用控制着氯苯在不同垂向深度的运移和分布.

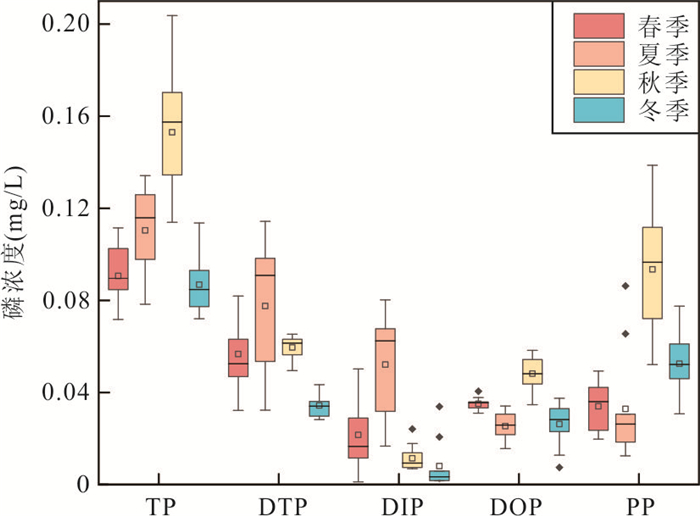
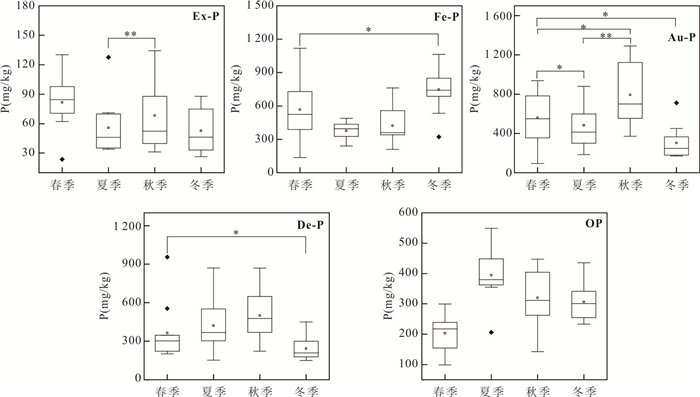
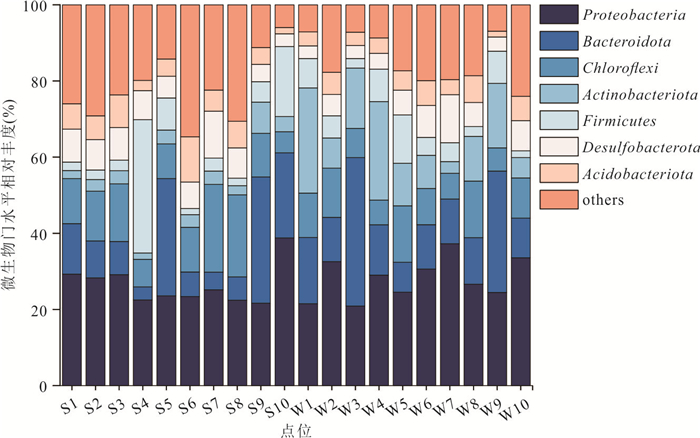
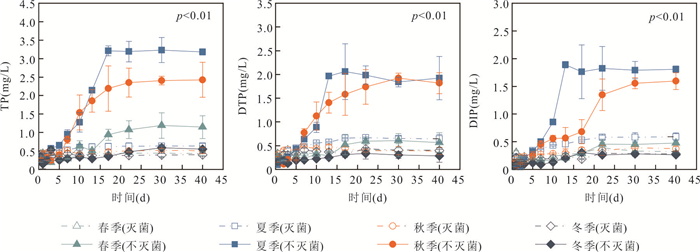
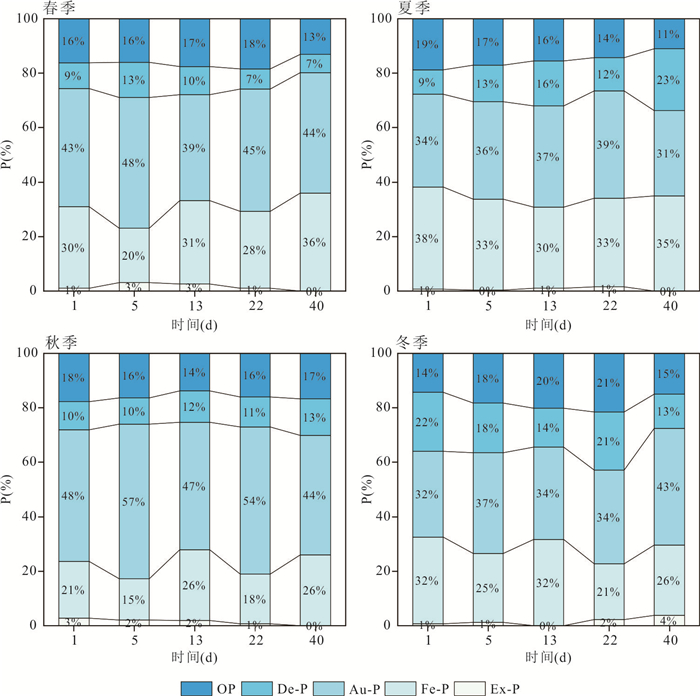
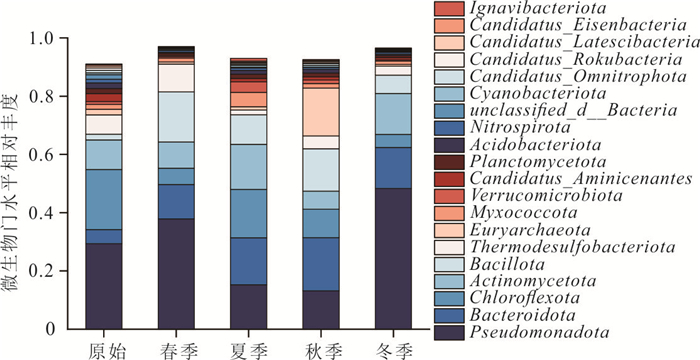
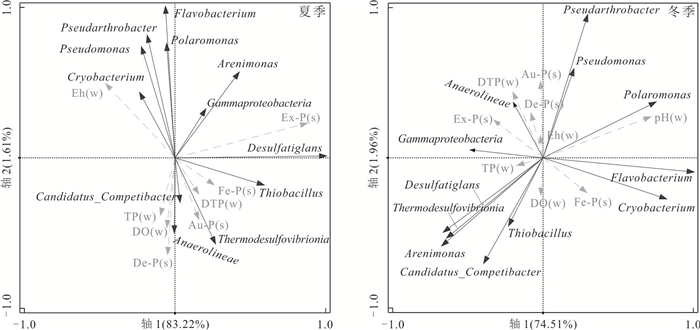
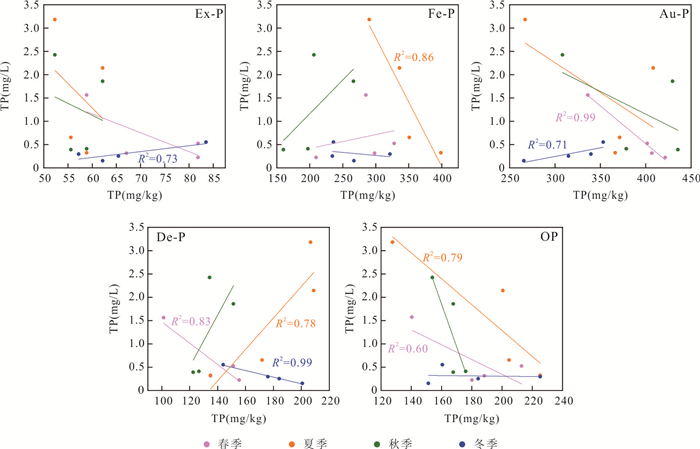
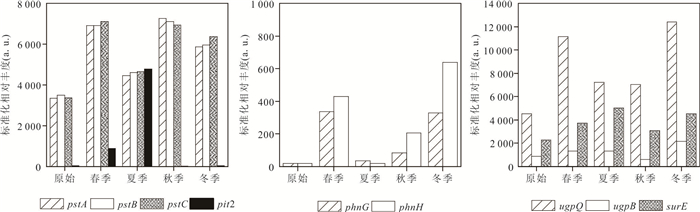
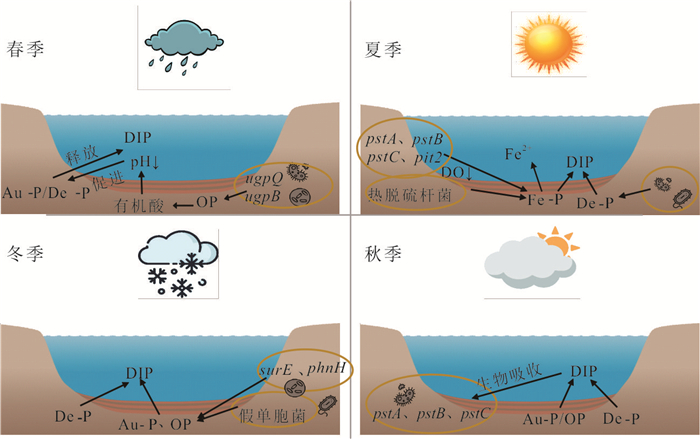
为阐明浅水湖泊沉积物内源磷季节性波动机制,通过野外采样和室内模拟(控制温度、溶解氧等关键参数)不同季节上覆水环境,结合沉积物磷形态提取与微生物功能基因定量技术,系统揭示了内源磷转化的季节性规律与驱动机制.研究结果表明浅水湖泊内源磷的季节性波动是受上覆水环境驱动的“矿化-溶解-吸收-储存”过程转换:春季以有机磷矿化(ugpQ高表达)促进钙磷溶解(减少70.56 mg/kg),夏季在缺氧背景下表现为铁磷还原溶解(减少108.55 mg/kg)并伴随低亲和力磷转运基因(pit2)升高的释放-吸收,秋季以非生物钙磷溶解(减少70.55 mg/kg)与高亲和力磷转运系统(pst高表达)介导的磷吸收并存;冬季碳-磷裂解酶系统基因(phn高表达)活化促使难降解磷利用.本研究深化了对内源磷波动生物化学耦合机制的理解.
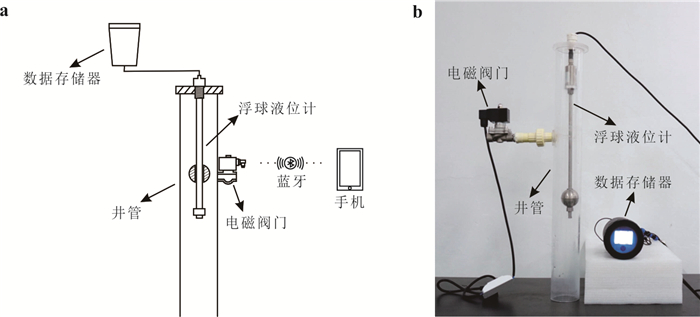
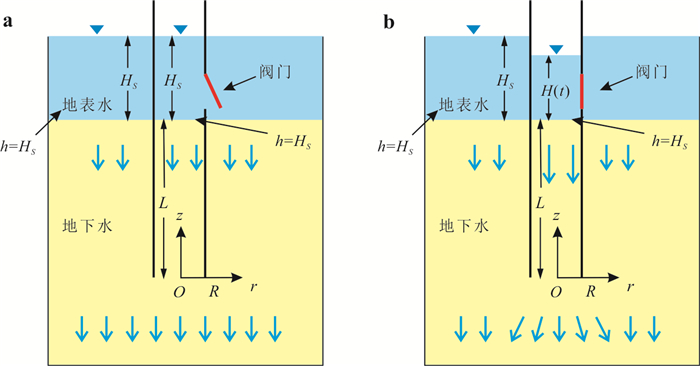
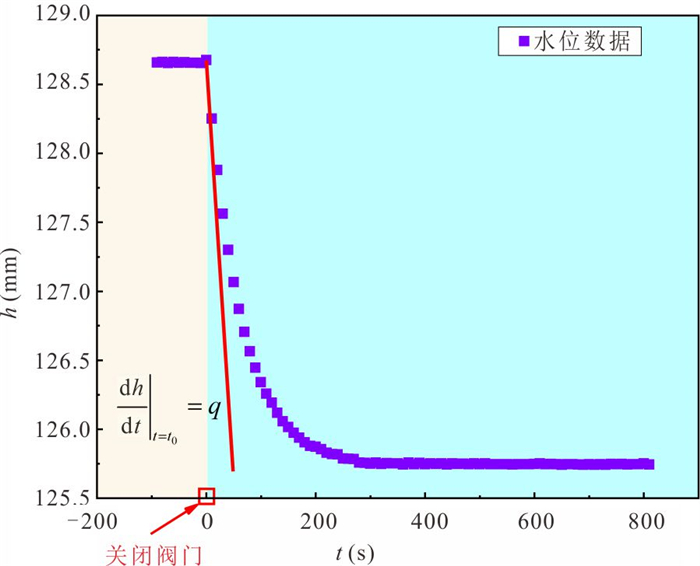
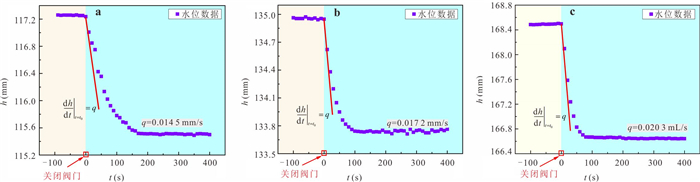
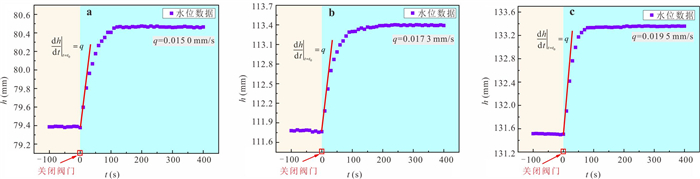
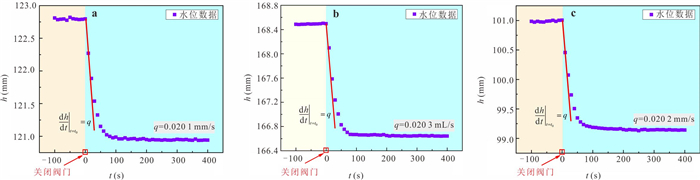
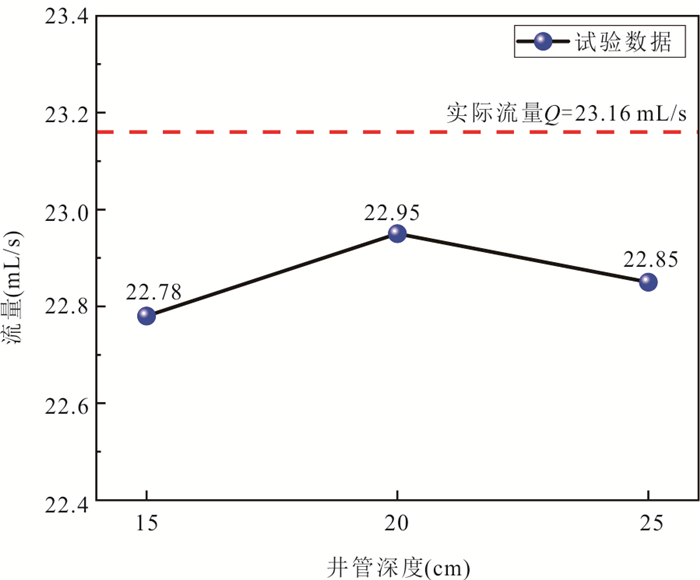
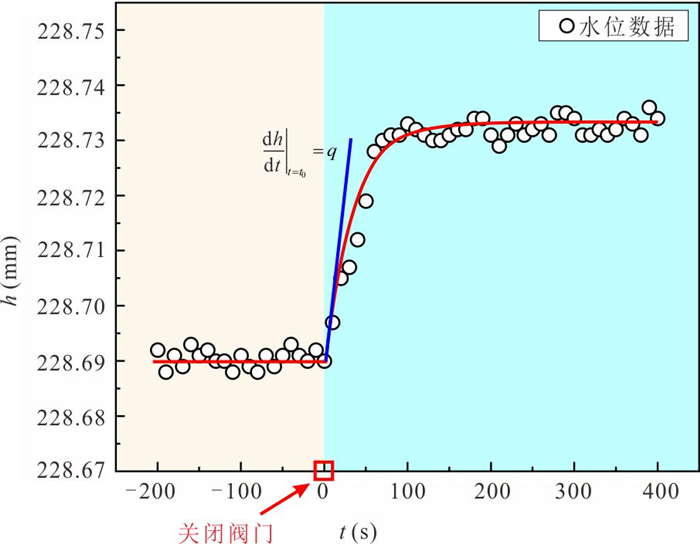
定量评估潜流带水流交换通量对区域水循环过程中物质、能量迁移转化和污染物修复治理等具有重要意义.然而,受河床非均质性及评估计算方法的限制,传统方法难以实现点尺度原位定量监测.本研究提出一种利用自动渗流仪监测评估地下水-地表水交换通量的方法,并开展室内和野外验证试验.结果表明:该方法能精准监测评估地下水补给地表水和地表水补给地下水两种交互模式下的交换通量,试验相对误差均小于3%;仪器插入含水层的深度对通量评估结果影响不显著,表明仪器稳定性强;野外试验中仪器能有效捕获地下水排泄过程的地下水微动态,计算得到交换通量为0.064 8 m/d.本研究为潜流带交换通量评估提供参数与技术支撑.


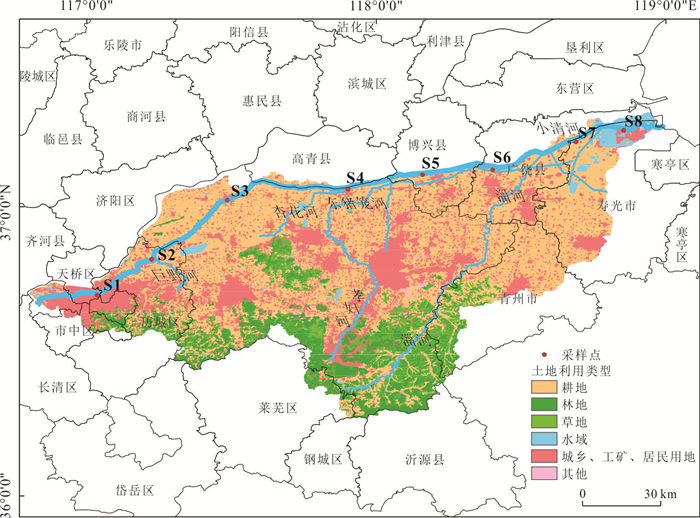
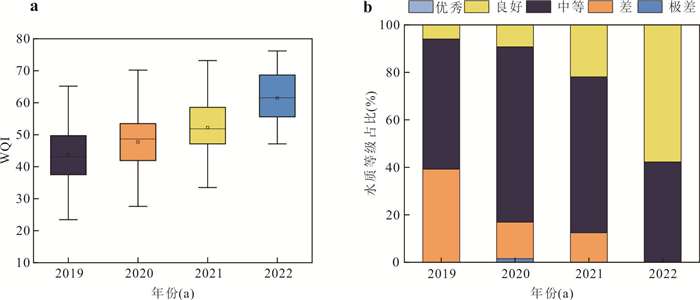
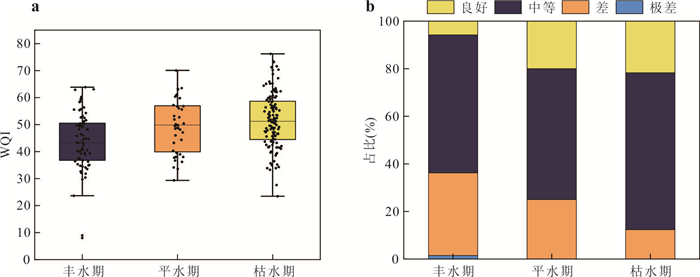
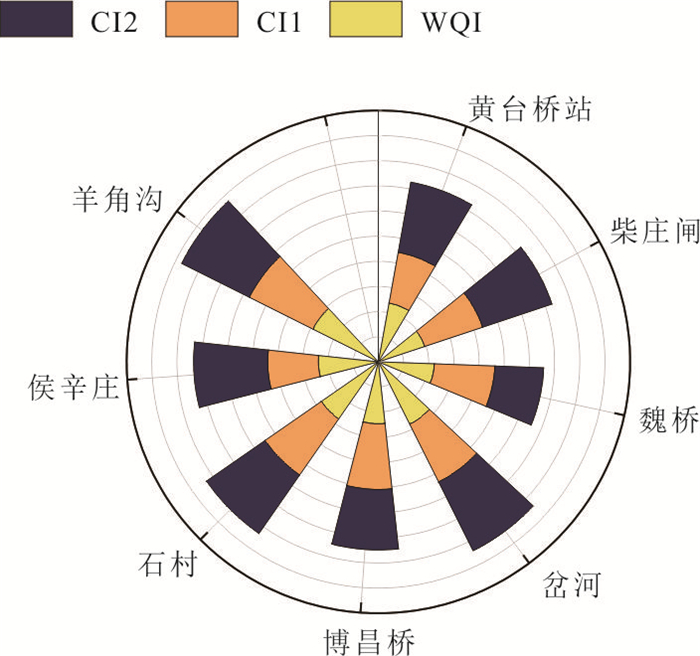
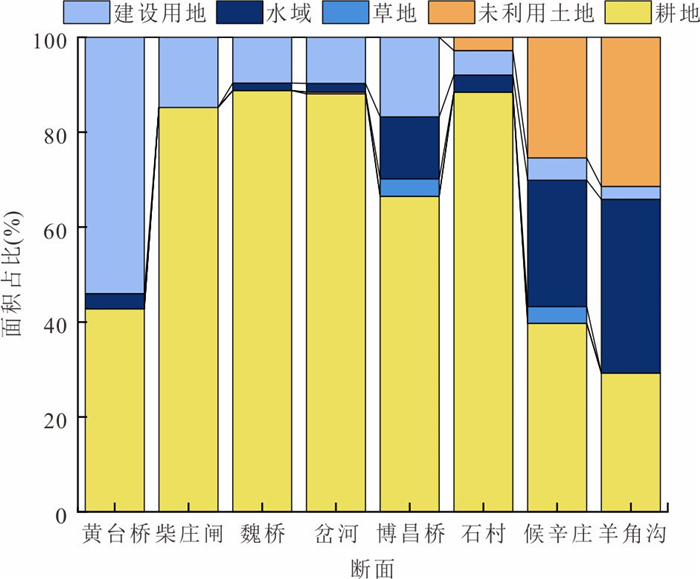
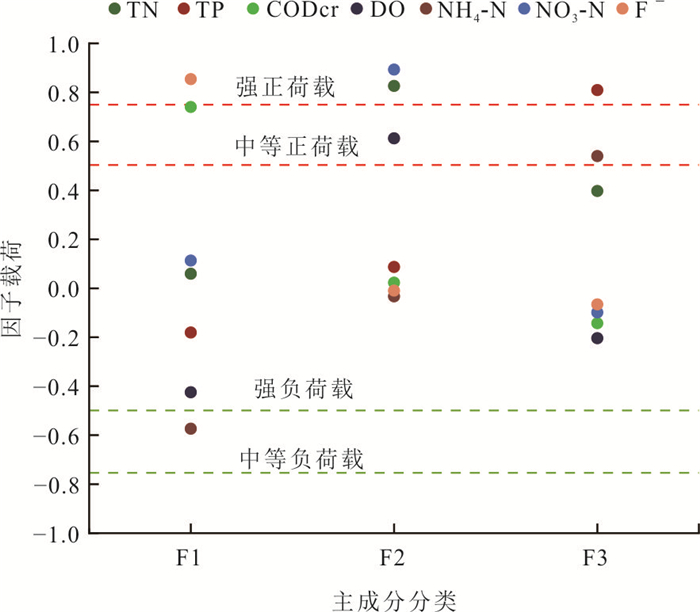
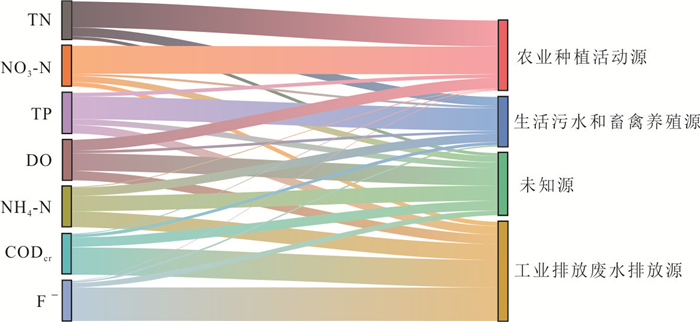
河流作为人类及其他生物赖以生存的重要自然生态系统,其水质状况直接关系到生态安全与可持续发展.为探究小清河干流水质时空变化特征,基于2019—2022年的水质监测数据,采用综合水质指数法(water quality index,WQI)分析小清河干流水质时空变化特征,并利用绝对主成分-多元线性回归模型解析干流污染物来源及其贡献率.结果表明:2019—2022年小清河干流水质年均WQI值呈现增加趋势,水质等级从“中等”转变为“良好”;水质状况在季节尺度上未呈现显著波动,但丰水期WQI均值相对较低.空间上,小清河干流水质WQI值总体上表现为中游<上游<下游,水质较差的区域主要分布在中上游,尤其是干流沿岸建设用地和耕地面积占比较大的地区.源解析结果显示,干流污染物来源较为复杂,主要为工业废水排放源(25.81%)、农业种植活动源(24.92%)、生活污水排放和畜禽养殖源(17.60%);干流各监测断面的污染物来源组成相似,然而,其污染源的贡献结构存在差异,这种差异与沿岸的土地利用方式及人类活动强度密切相关.研究结果可为小清河流域的污染防控与治理决策提供关键科学依据.
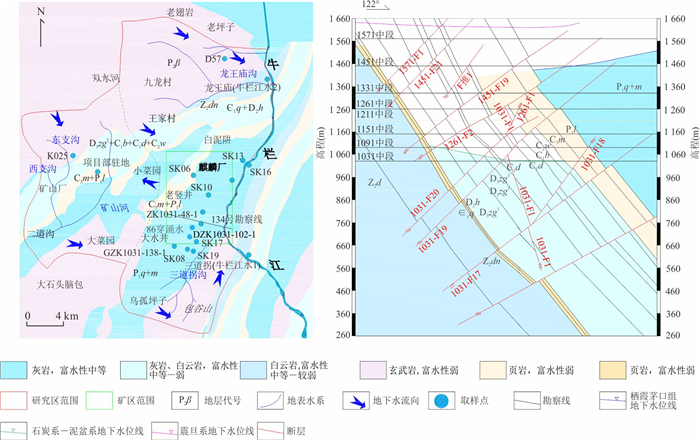
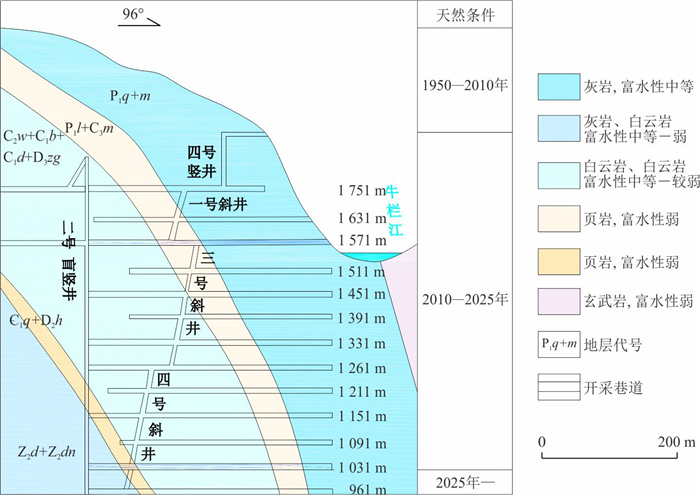
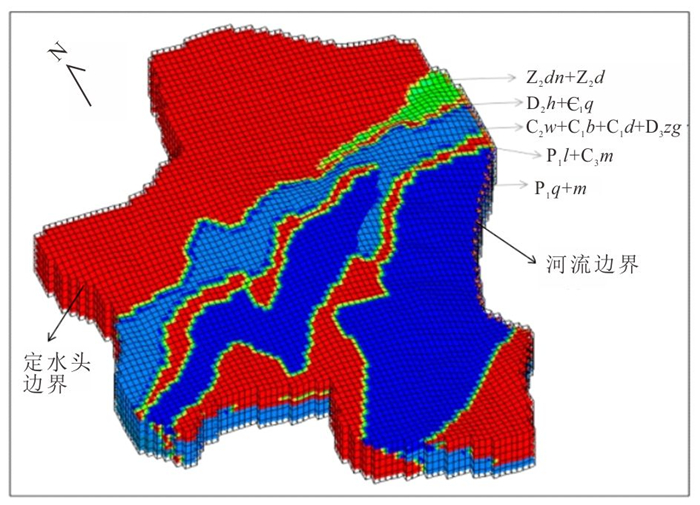
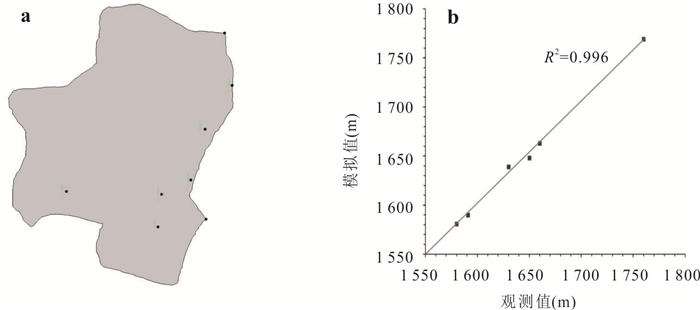
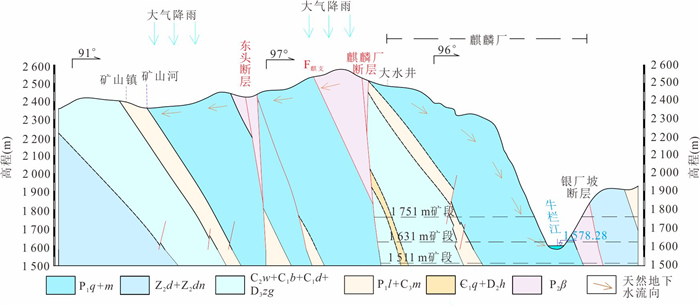
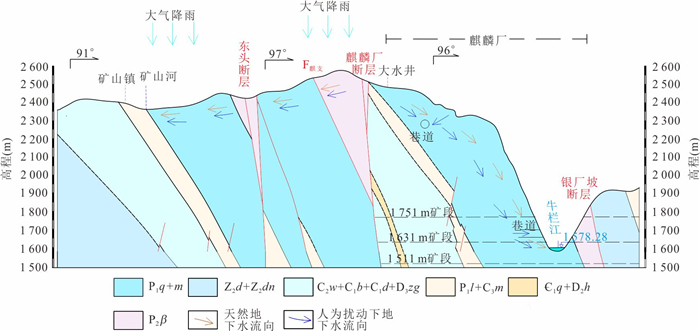
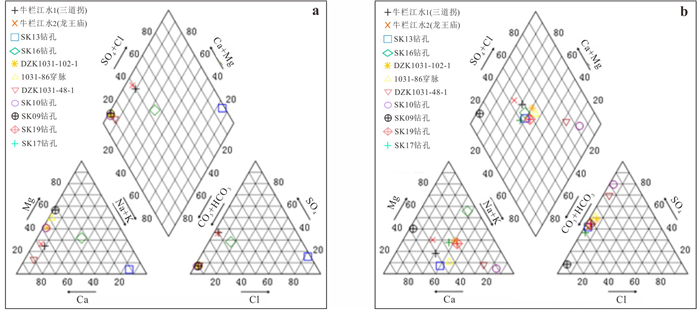
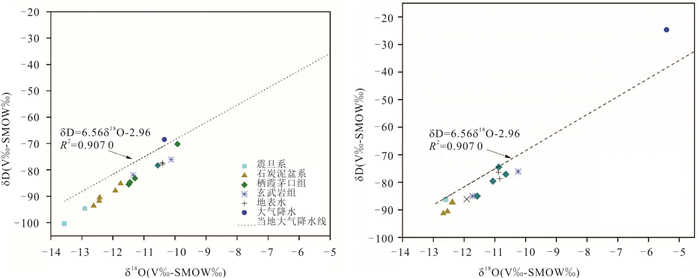
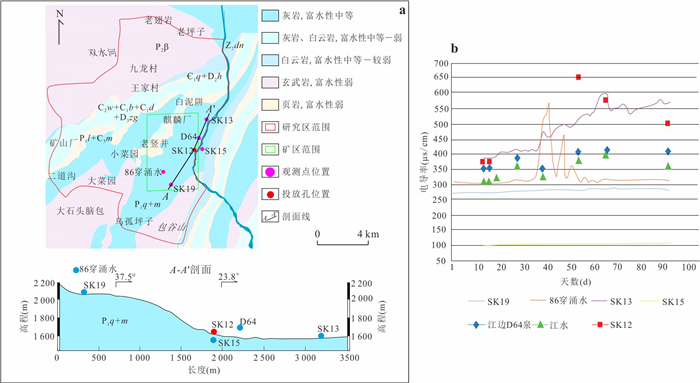
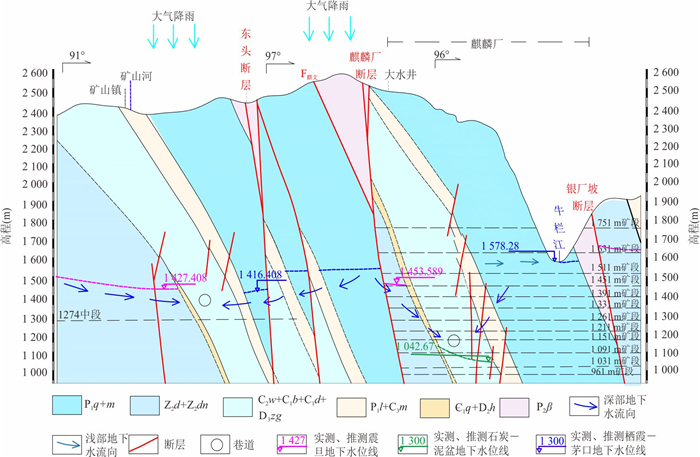
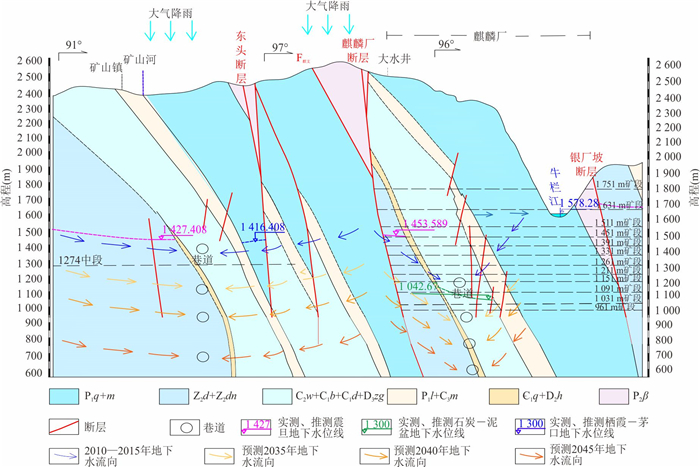
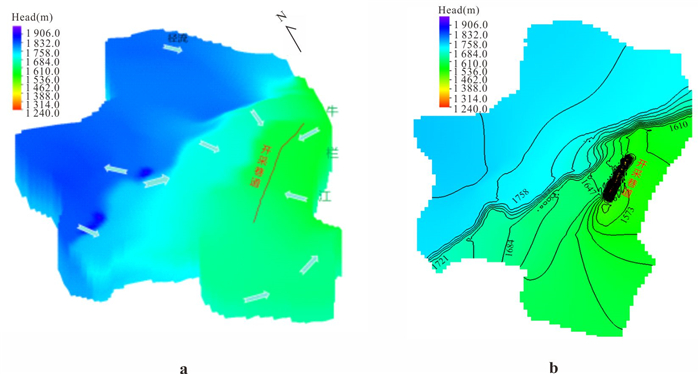
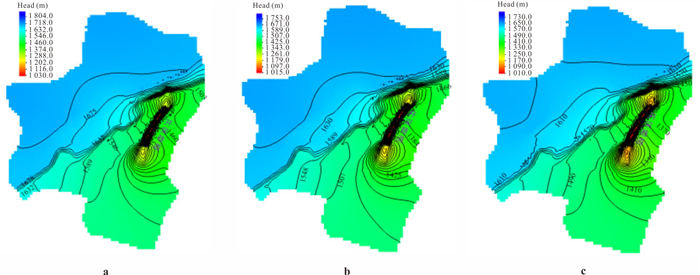
为研究采矿活动影响下的复杂岩溶矿区地表水-地下水相互作用模式.借助水化学及同位素技术、示踪实验、数值模拟等方法,发现天然条件下,地下水以大气降水补给为主,沿分水岭向牛栏江排泄.开采干扰下(1950—2010年),浅层开采对区域地下水流动系统影响有限,仅引起局部水位下降,改变局部径流方向.干扰强化条件下(2010年后)第一时期(2010—2025年)呈现“浅部弱自然循环-深部强人工排泄”的特征,浅部含水层与牛栏江弱连通,深部地下水向巷道排泄;第二时期(2025年后)以持续扩展的降落漏斗为特征,预测往后第5、10、20年的水位下降约64 m、103 m、120 m.综上所述,矿区岩溶地表水-地下水交互受控于矿区岩溶水文地质结构与采矿活动.研究成果可为会泽铅锌矿区制定科学有效的防排水方案提供理论依据.
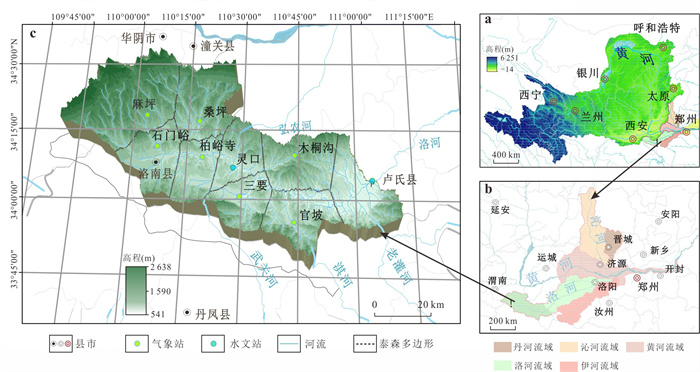
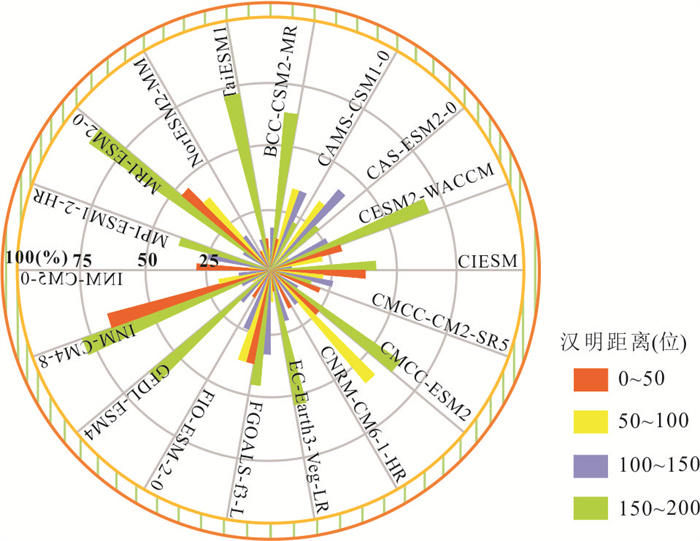
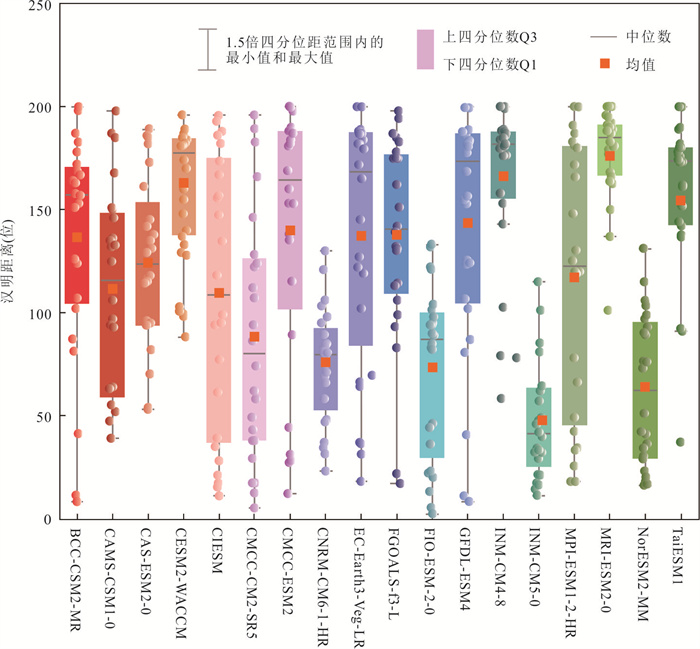
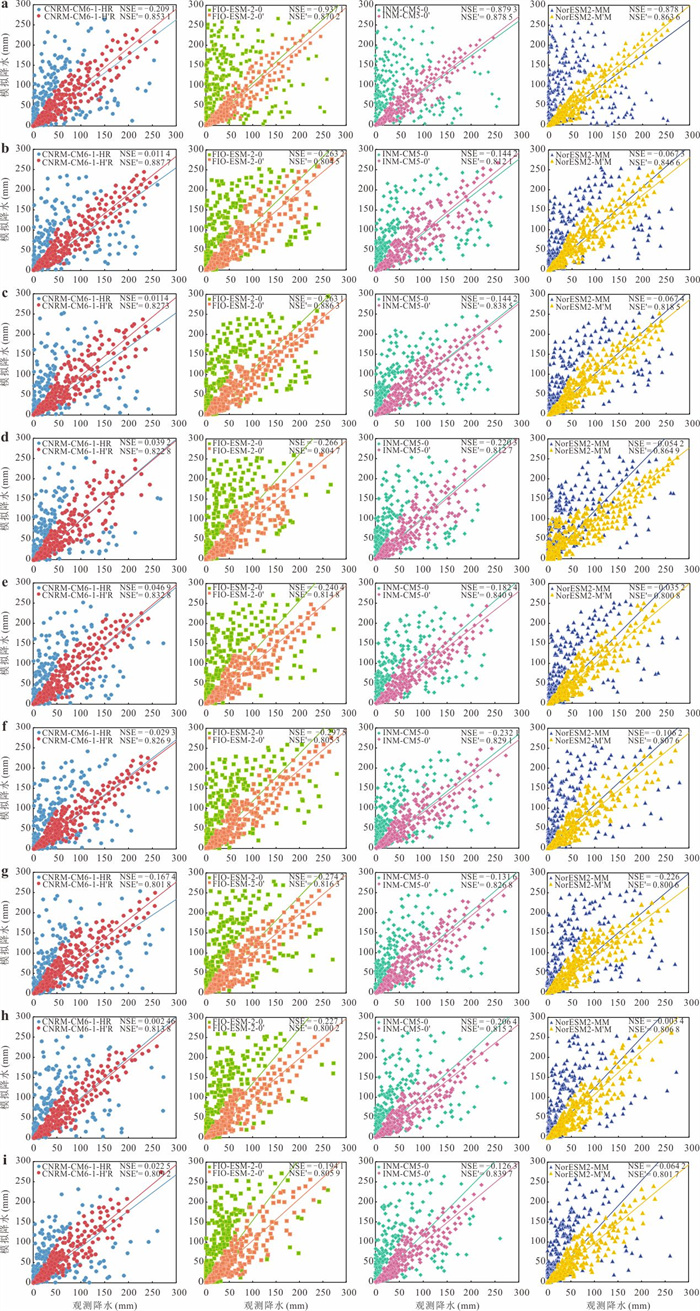
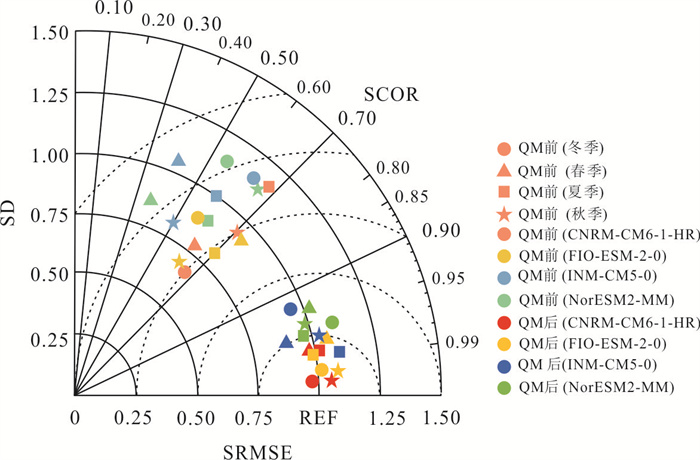
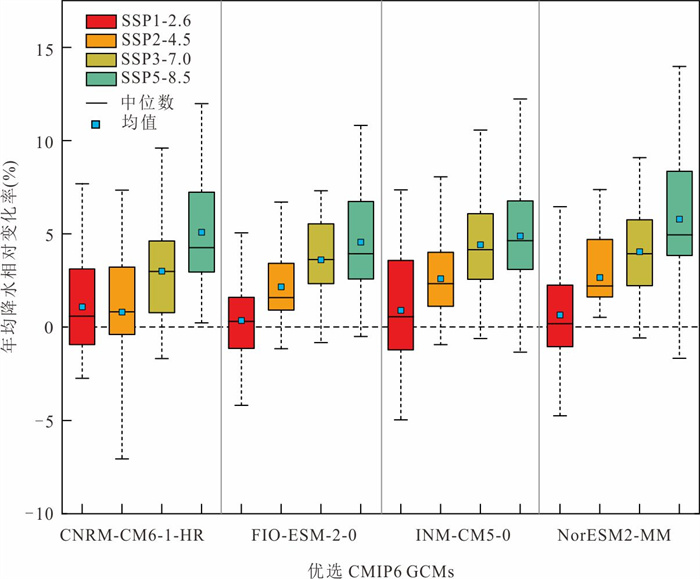
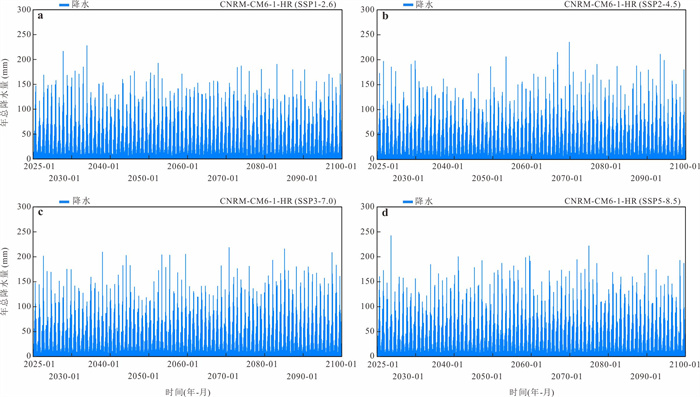
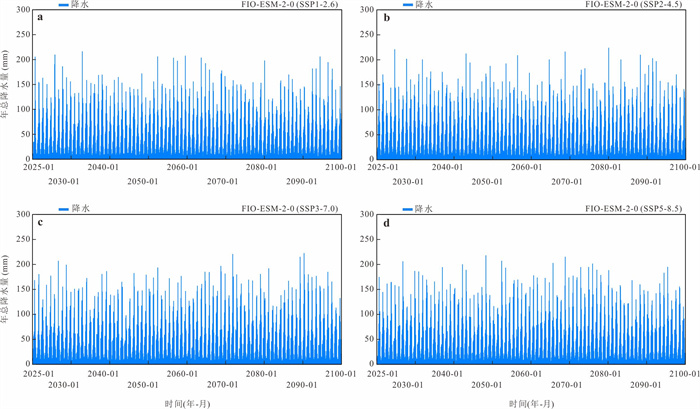
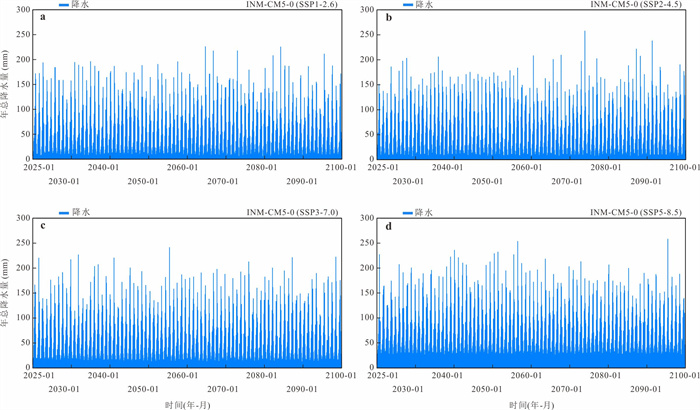
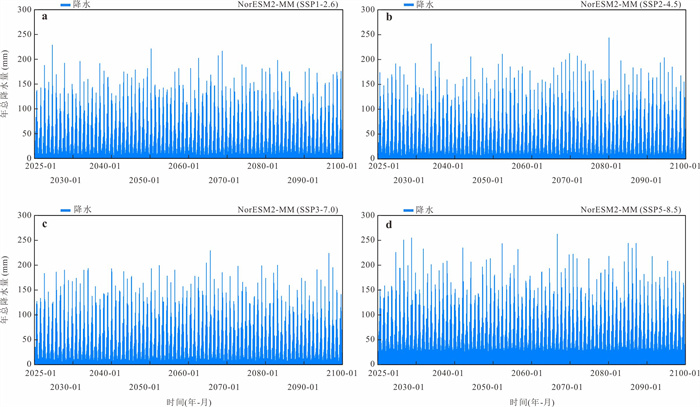
气候变化导致流域极端水文事件频发,评估CMIP6气候模式(global climate models,GCMs)对降水的模拟能力并预测其未来变化趋势对水文研究至关重要.基于1976—2000年18个GCM及卢氏流域9个站点逐日降水数据,引入考虑时空相关性的改进哈希算法(improved Hashing algorithm,ISHA)优选GCMs,突破传统SHA固定网格划分局限,结合非参数分位数映射法(quantile mapping,QM)误差订正,预测2025—2100年4种SSP情景下降水变化. CNRM-CM6-1-HR、FIO-ESM-2-0、INM-CM5-0和NorESM2-MM表现最优;订正后最大月降水和多年平均降水偏差率由9.09%~16.04%、10.41%~23.12%降至0.27%~2.34%、0.48%~1.89%;未来年均降水相对变化幅度随排放情景升高而增大,在低排放情景下波动为-7.71%~10.50%,而在高排放情景下可达-1.89%~18.02%.本世纪中末期或面临降水增加风险,水资源调控与防洪减灾压力加剧.
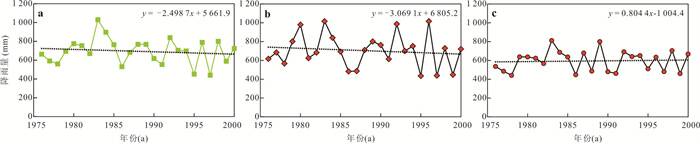
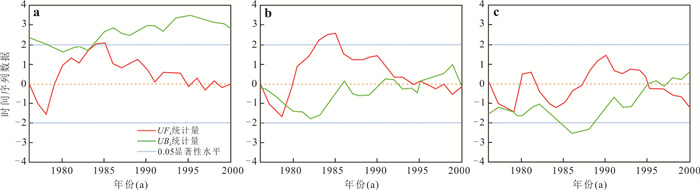
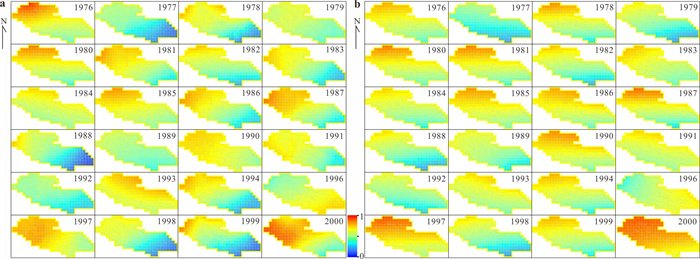
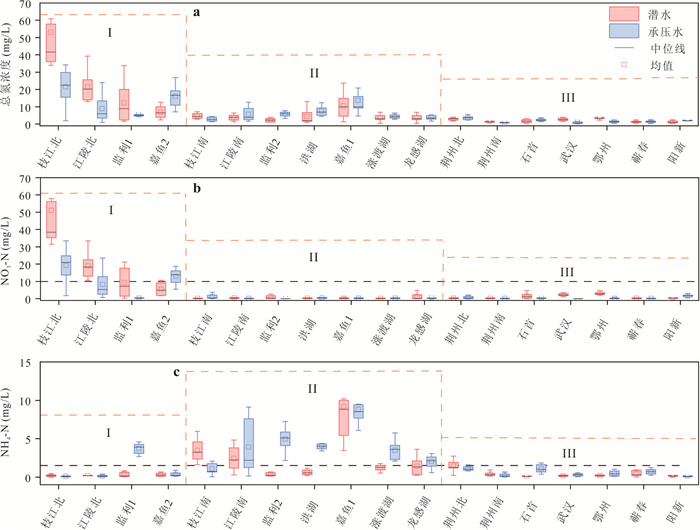
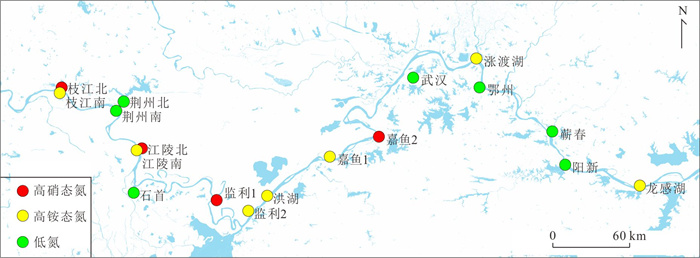
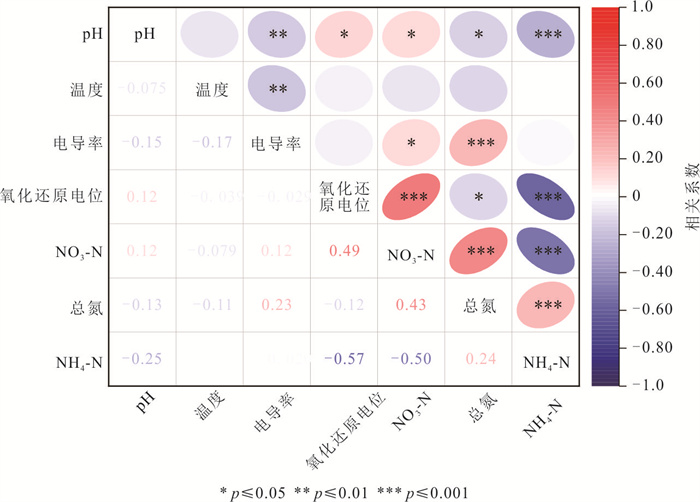
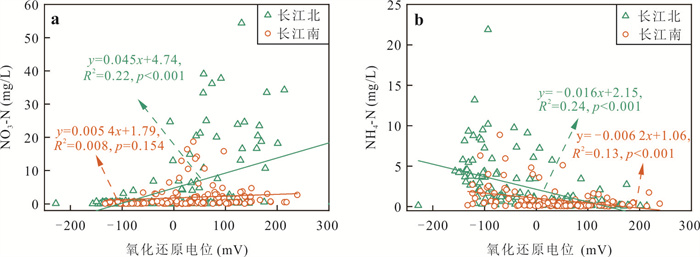
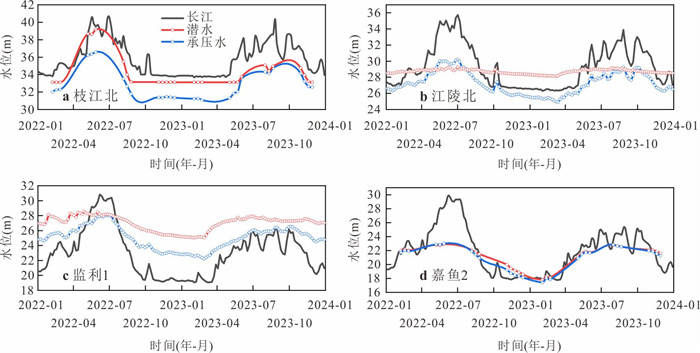
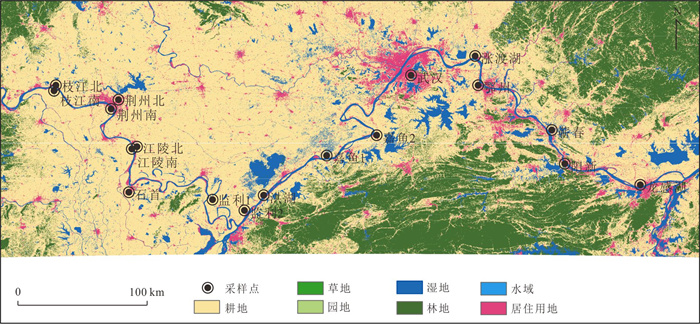
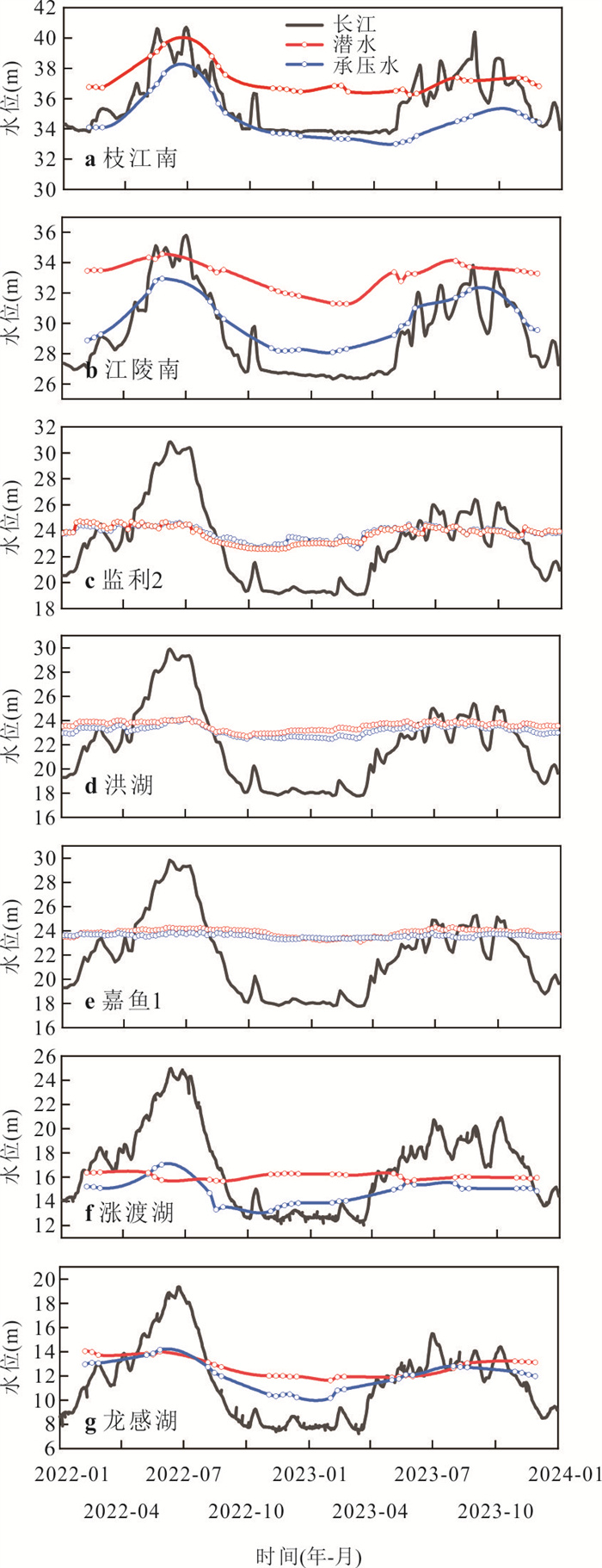
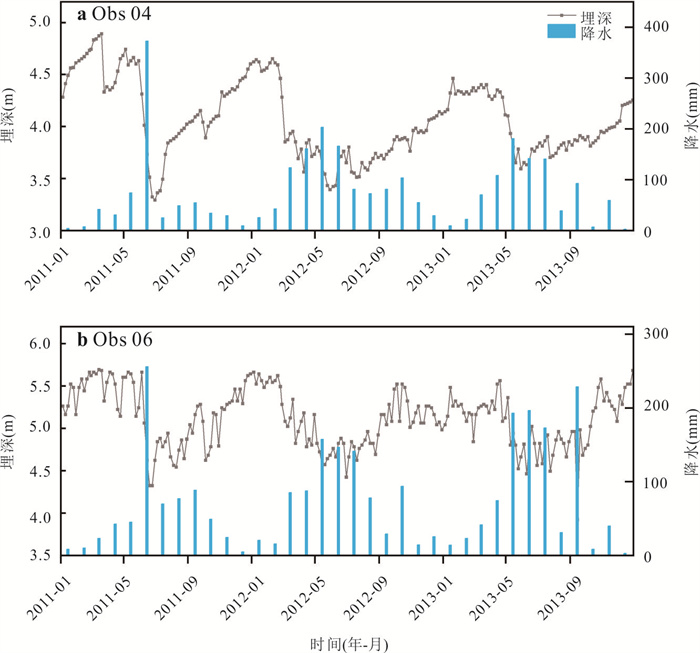
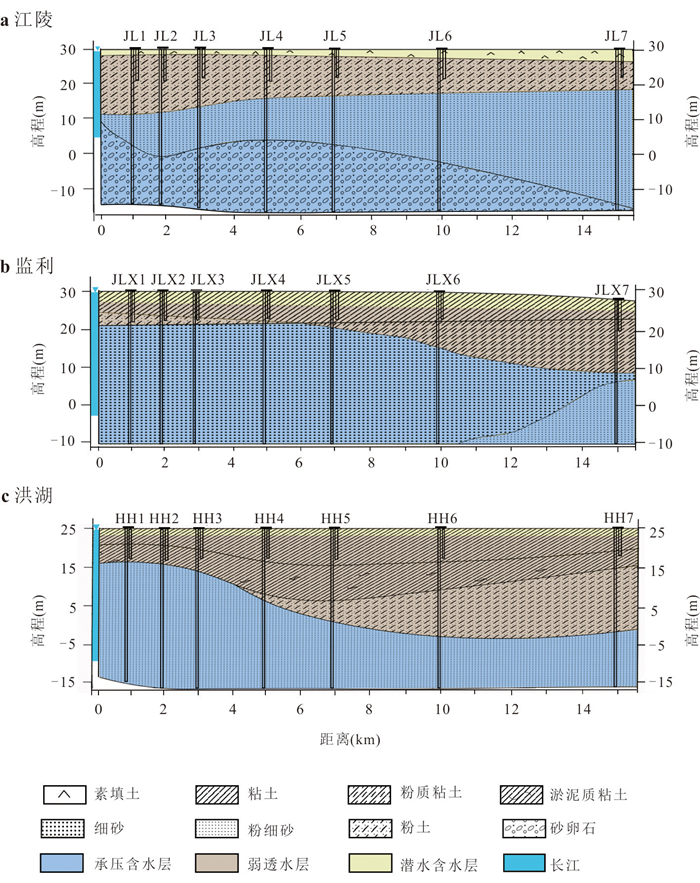
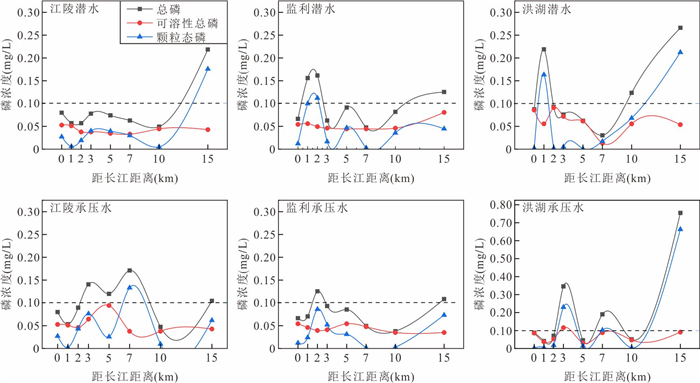
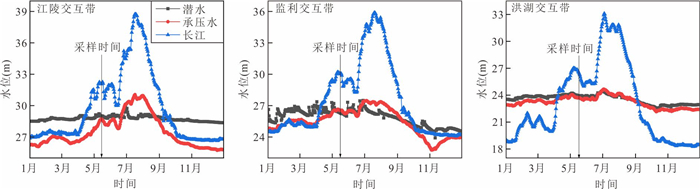
为了探究长江中游临江地下水中氮的赋存状态及地表水-地下水补排模式对氮富集的影响,对长江中游18个监测点两年8个季度的水文监测和288组水样分析,系统揭示了长江中游临江地下水中氮的富集特征及不同富集区中江水-潜水-承压水的补排模式的差异性.结果表明,长江中游临江地下水氮的富集差异性较大,研究区识别出高硝、高氨和低氮区3种氮的赋存模式;长江北侧地下水中氮的富集主要受氧化还原电位的调控,而南侧地下水中氮的富集受多种因素共同控制;高硝区主要出现在潜水有氮污染且潜水-承压水-江水均连通、以江水补给为主的承压水中;高氨区主要出现在潜水-承压水-江水间水力联系较弱或地下水向长江排泄为主的承压水中,不受潜水中氮污染的影响,其主要源于地质成因.该研究结果分别揭示了长江中游临江潜水和承压水中不同形态氮的富集特征及其与潜水-承压水-江水的连通性和补排关系之间的联系,为该区域氮的生物地球化学过程及氮来源解析提供了重要的科学依据.
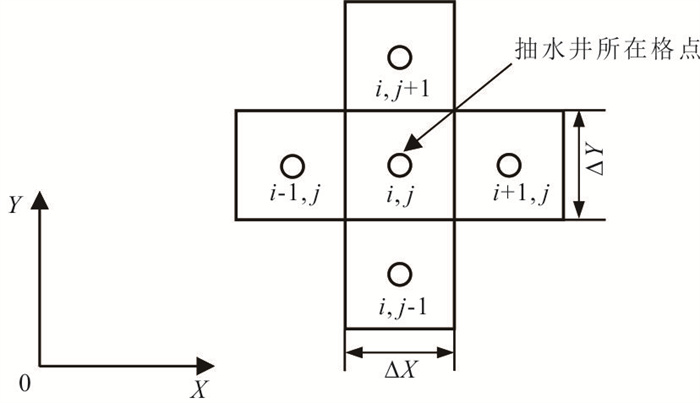
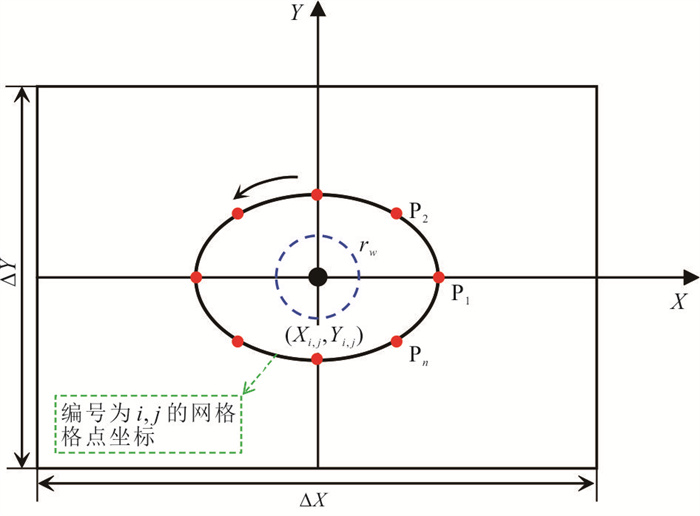
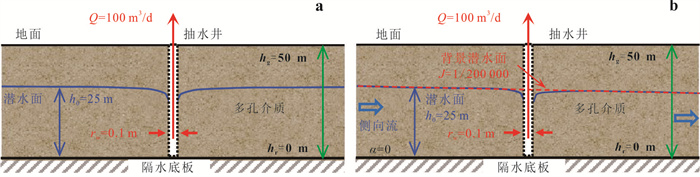
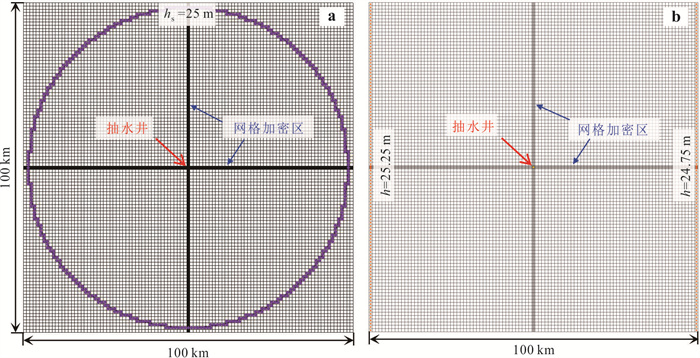
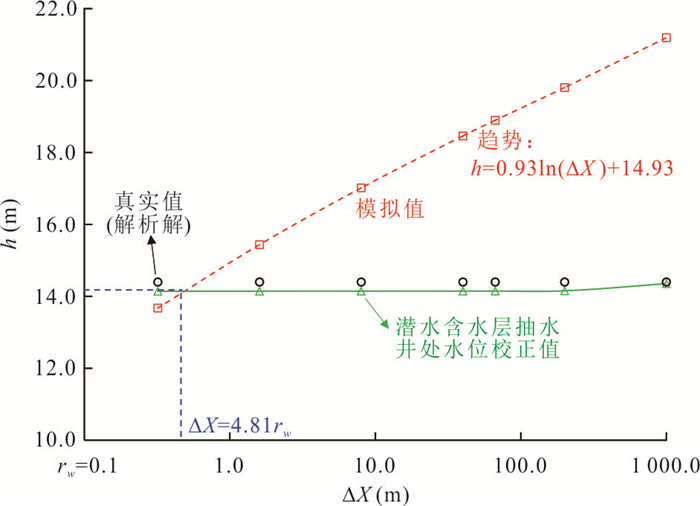
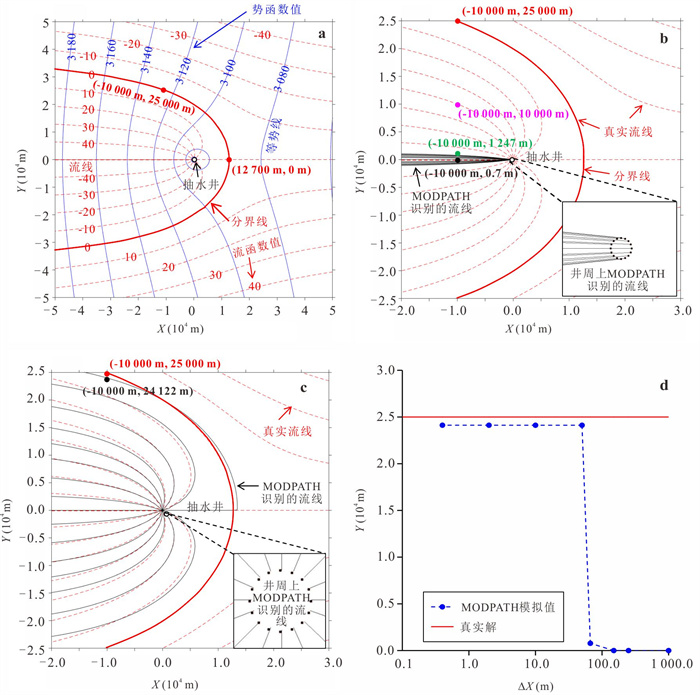
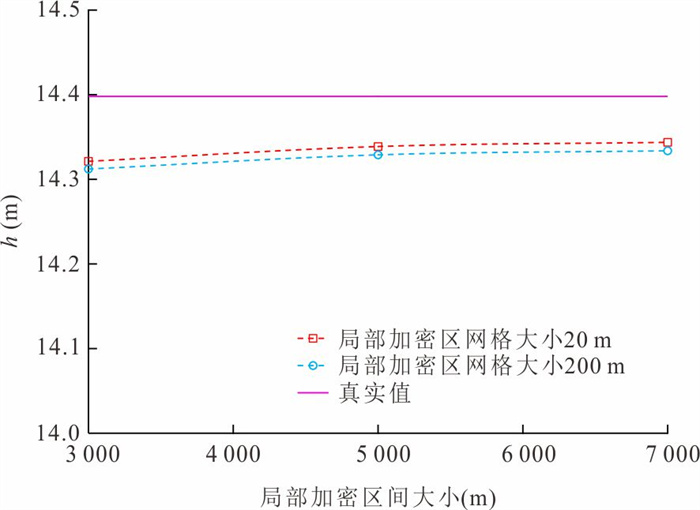
中心网格有限差分法模拟水位与流线是开展众多水文地质工作的基础.为了解决潜水含水层中抽水井处水位模拟误差问题并精确识别流线.本研究基于复势理论,推导了中心网格有限差分法抽水井处水位校正公式,耦合数值模型量化分析了水位校正对流线精度的影响.结果表明,校正公式可显著提升抽水井处水位模拟精度;同时明确了当离散网格尺寸约为井半径的5倍时,无需校正即可同时保证水位与流线的模拟精度.该研究为解决数值模拟中离散化带来的模拟误差提供了理论依据与实用判据.
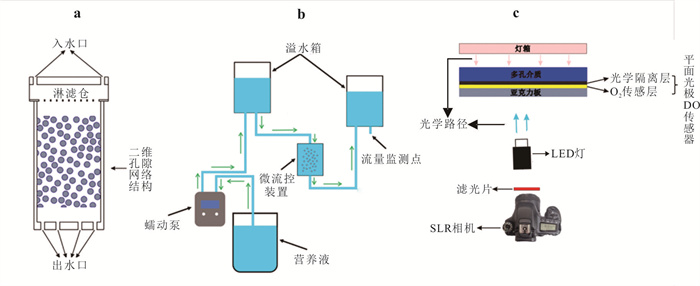
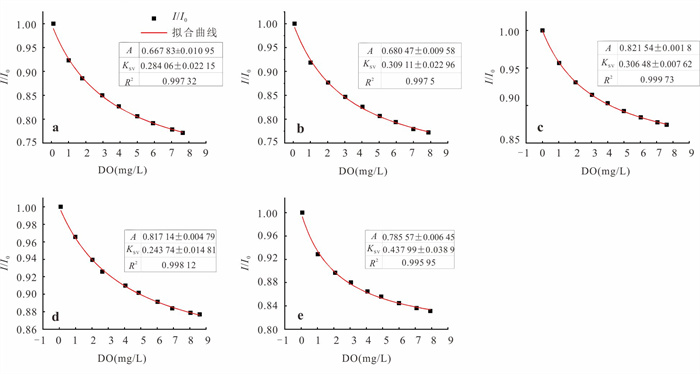
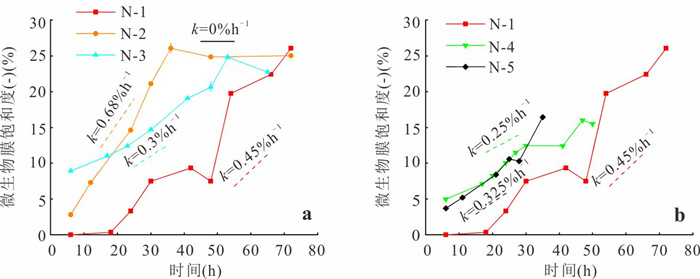
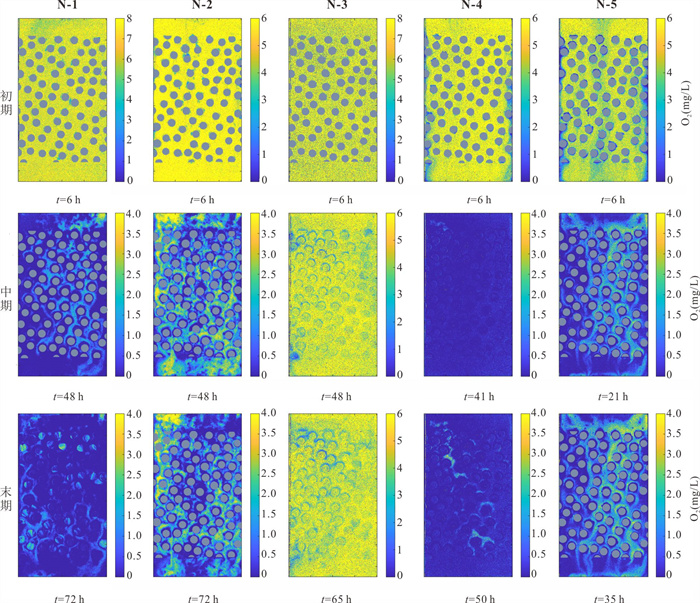
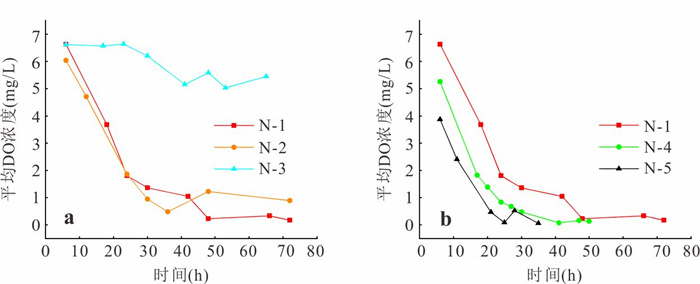
缺氧微区是多孔介质中重要的氧化还原反应热点区域,但对于其形成与演化机制并不完全清楚.基于自主构建的孔隙网络尺度微流控实验平台,结合微生物膜与溶解氧(dissolved oxygen,DO)原位可视化监测技术,系统研究了营养供给浓度与水动力条件对微生物膜生长及DO时空分布演化的影响机制,并在孔隙尺度下直接观测与解析了缺氧微区的形成与演化过程.微生物膜生长与营养供给浓度并非正相关.仅12.5 mg/L葡萄糖供给浓度搭配0.125水力梯度能使DO空间分布始终呈现“全局富氧-局部缺氧”的格局,从而维持持续性缺氧微区,其余场景仅能形成短暂性缺氧微区.营养供给浓度与水动力条件的协同作用,通过调控DO供给与消耗的动态平衡,主导了持续性缺氧微区的形成与演化.


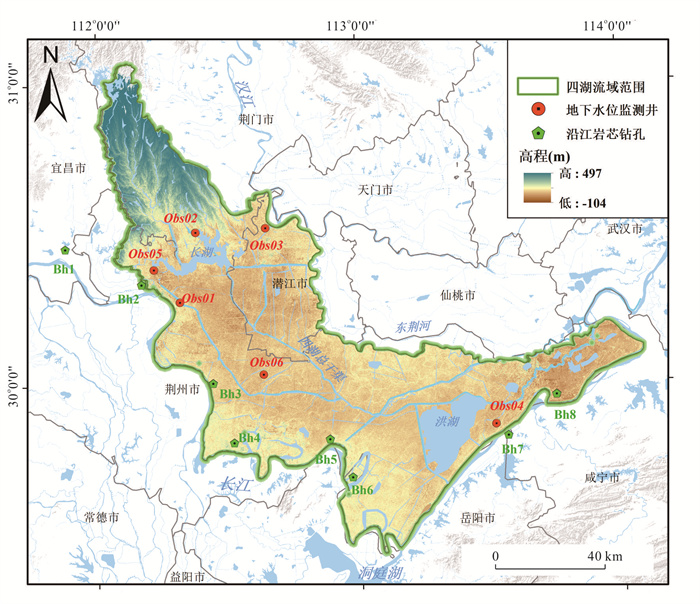
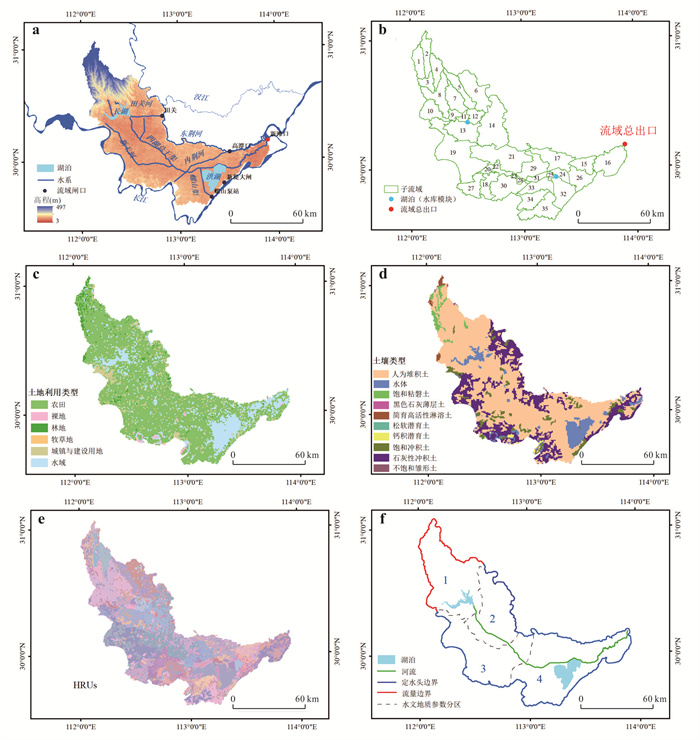
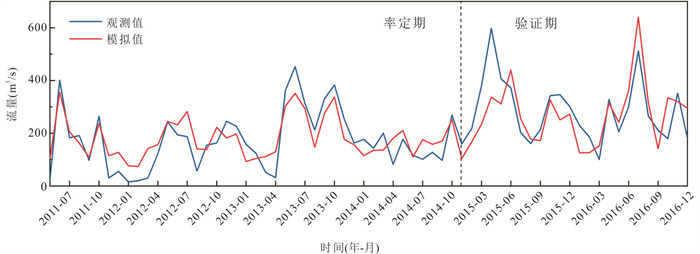
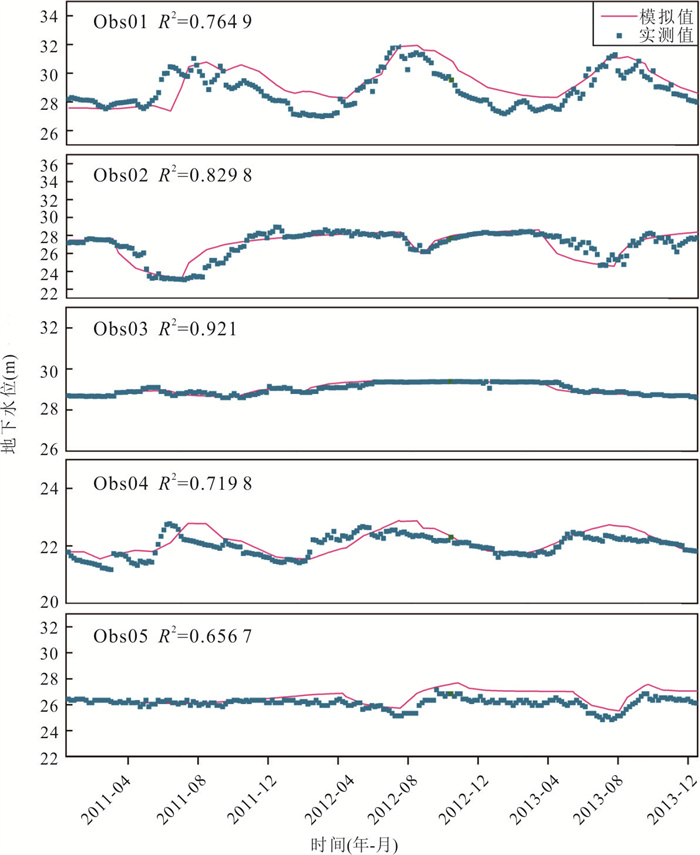
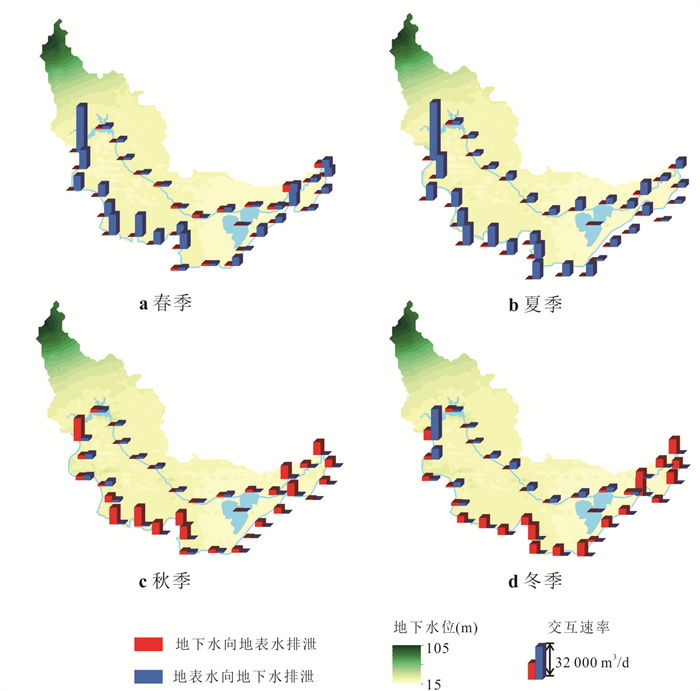
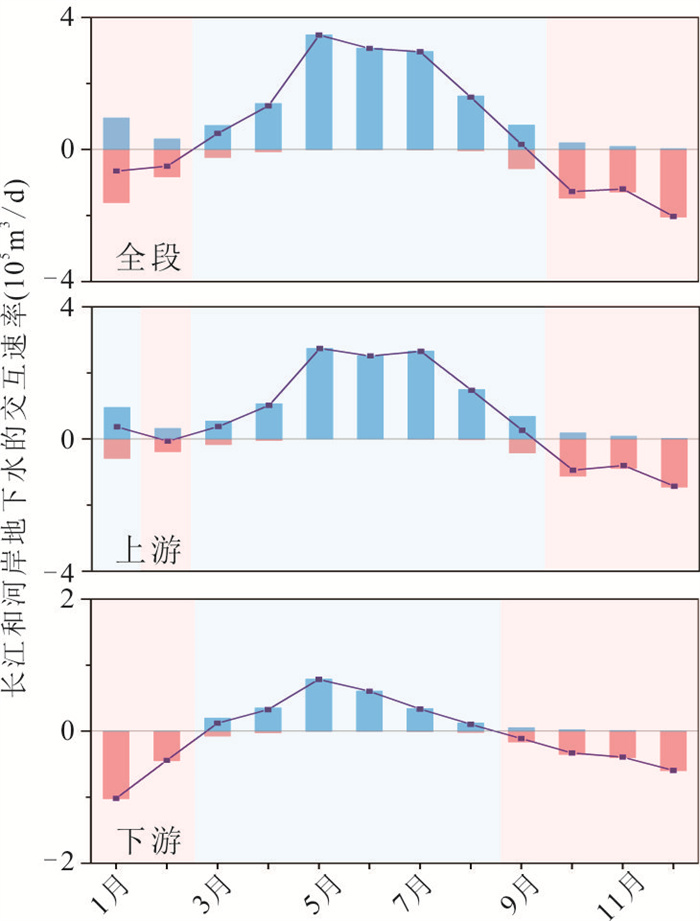
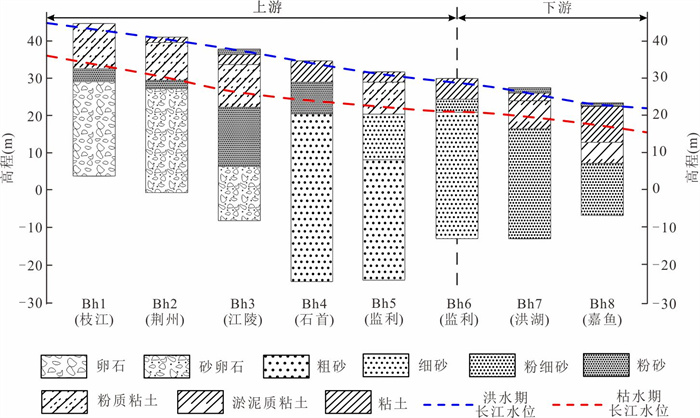
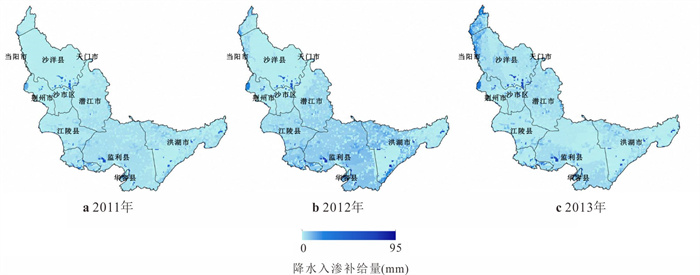
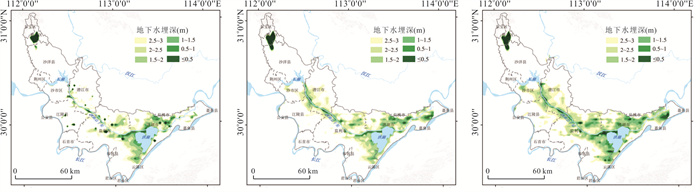
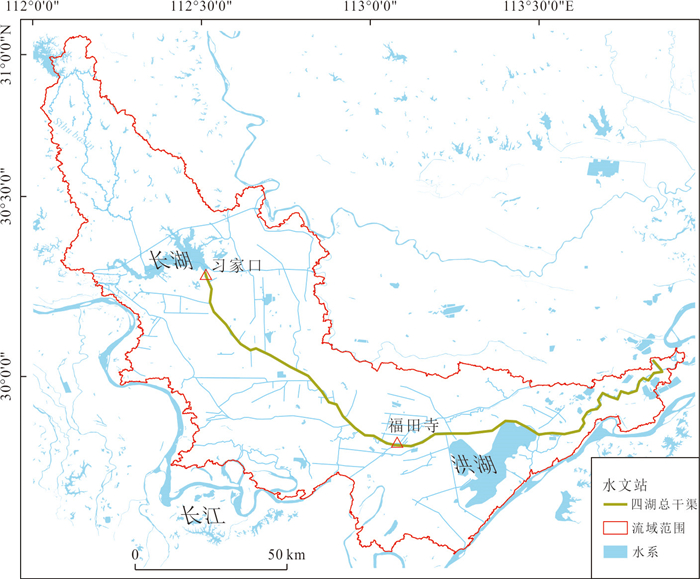
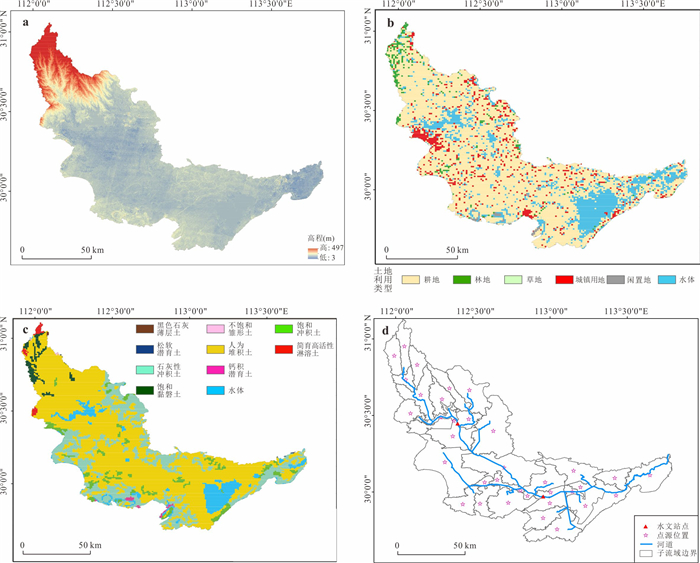
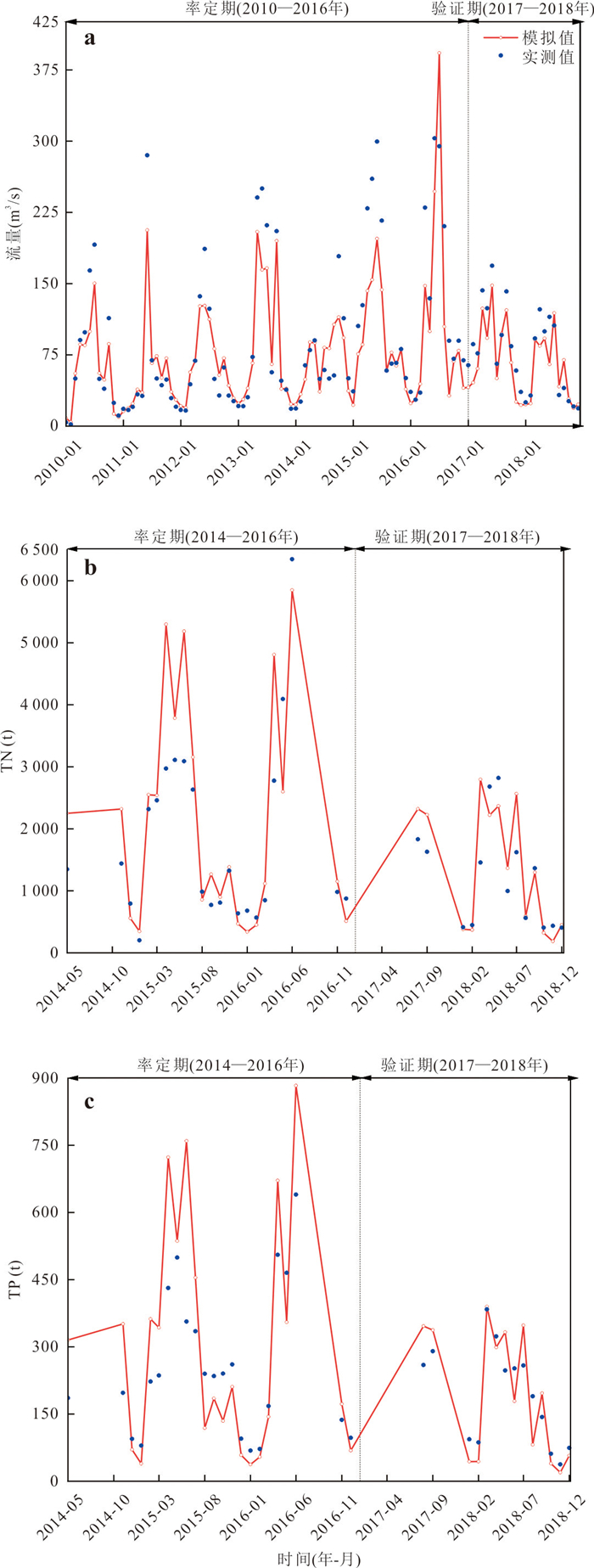
位于江汉平原的四湖流域是长江中游典型的江-河-湖-田多端元系统,生态环境问题突出,为了精确量化四湖流域内主要水系和地下水的交互速率,分析影响流域内土壤潜育化程度的主要因素.利用SWAT-MODFLOW模型构建四湖流域地表水-地下水耦合模型,围绕模型结果,对四湖流域内地表水和地下水交互速率的时空差异以及冷浸田分布情况进行分析探讨.研究结果表明,耦合模型对径流与地下水的模拟效果较好;长江与地下水交换呈现明显季节性转化,春夏季以江水补给地下水为主,秋冬季则地下水排泄入江;流域内长湖交互强度高于洪湖,总干渠上下游表现出不同的交换模式;土壤潜育化风险区(地下水埋深<3 m)主要分布于洪湖周边、总干渠沿线及监利市西北部,受降水入渗、地形和土壤利用类型共同影响.本研究为四湖流域水交换过程与土壤渍涝风险提供了定量依据,可为区域水资源管理与生态保护提供科学支撑.
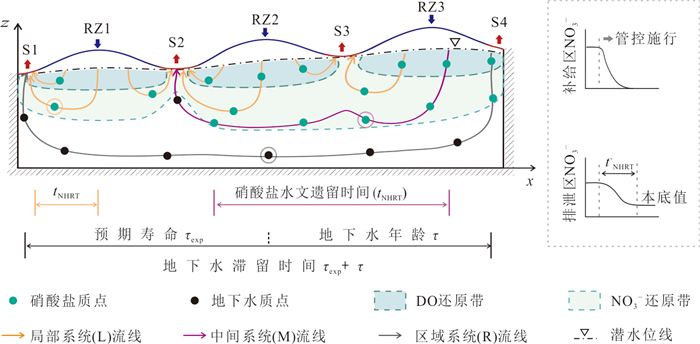
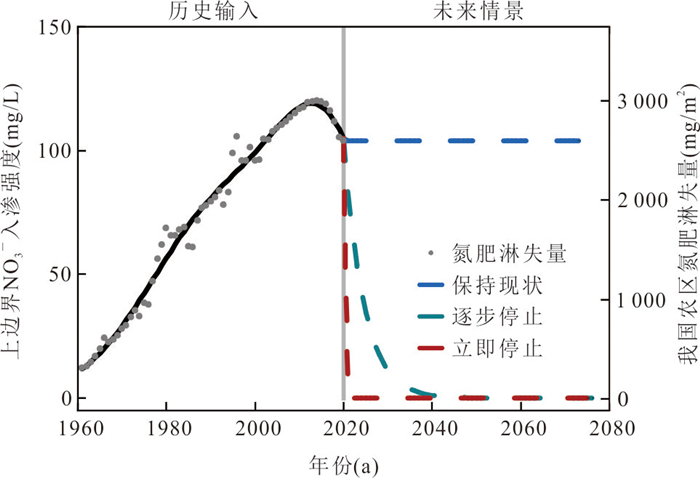
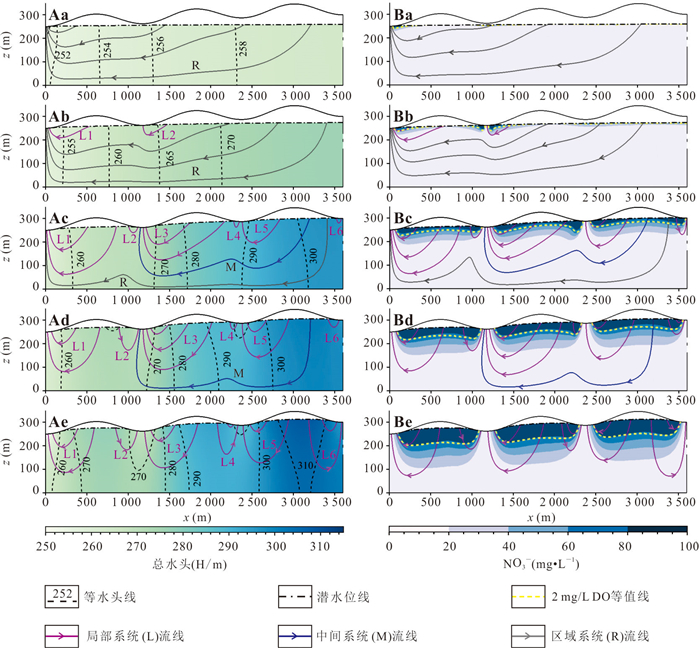
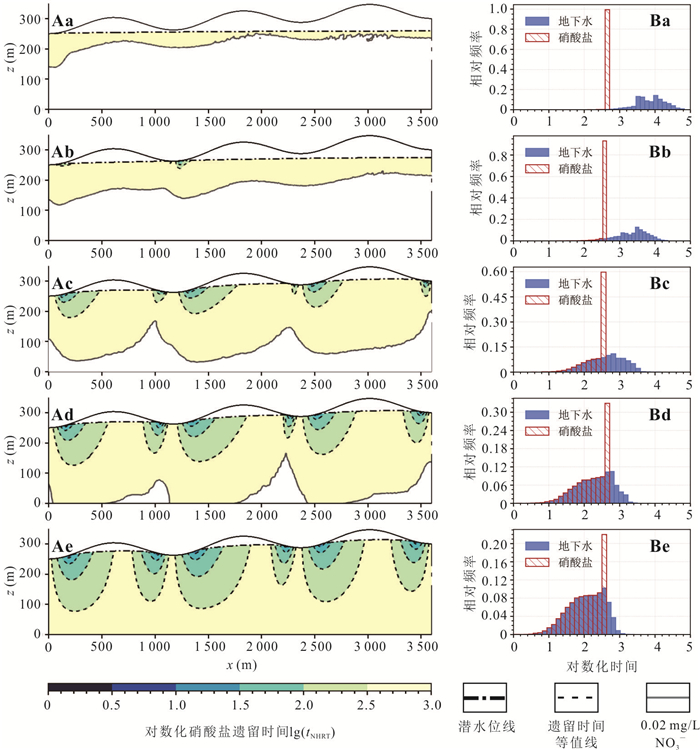
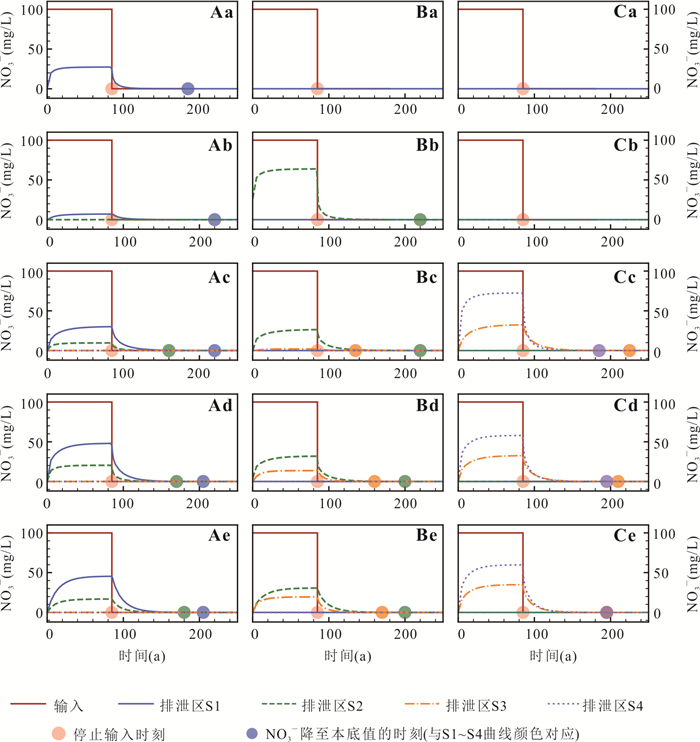
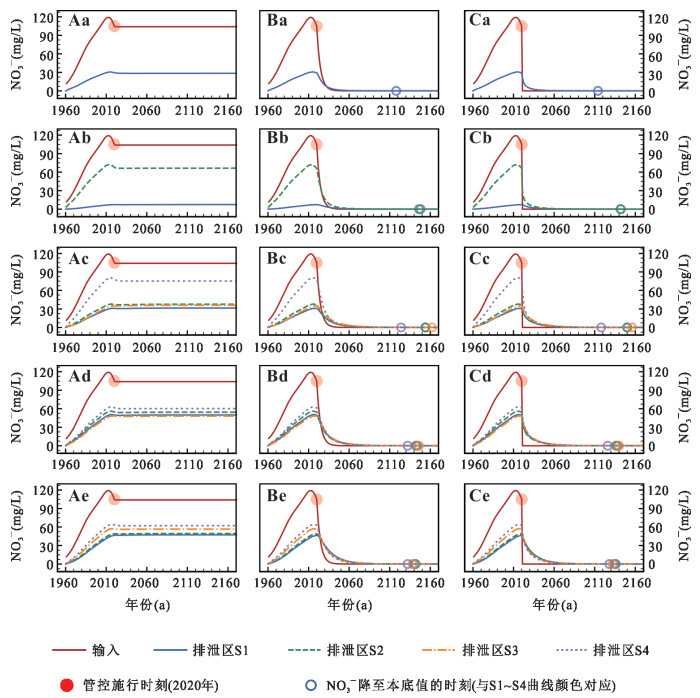
以小型砂质盆地为例,基于二维Tóth模型探究了硝酸盐在多级次地下水流系统中的水文遗留时间特征.随着入渗强度增大,水流系统从单一区域系统、嵌套系统向单一局部水流系统转化,盆地硝酸盐平均水文遗留时间递减,但较长遗留时间(250~500 a)占比始终最大.排泄区硝酸盐浓度受相邻局部水流系统主导,其发育深度越大,水文遗留时间越长.若不削减输入,排泄区硝酸盐浓度经2~8 a稳定后无法下降,立即停输比逐步停输使硝酸盐提前4~6 a恢复本底值.控制地下水硝酸盐污染需优先管控相邻局部水流系统硝酸盐输入,或通过调控补给强度改变局部水流系统的发育深度,但快速削减地下水硝酸盐输入量无法显著改善管控措施对水质改善的滞后性.
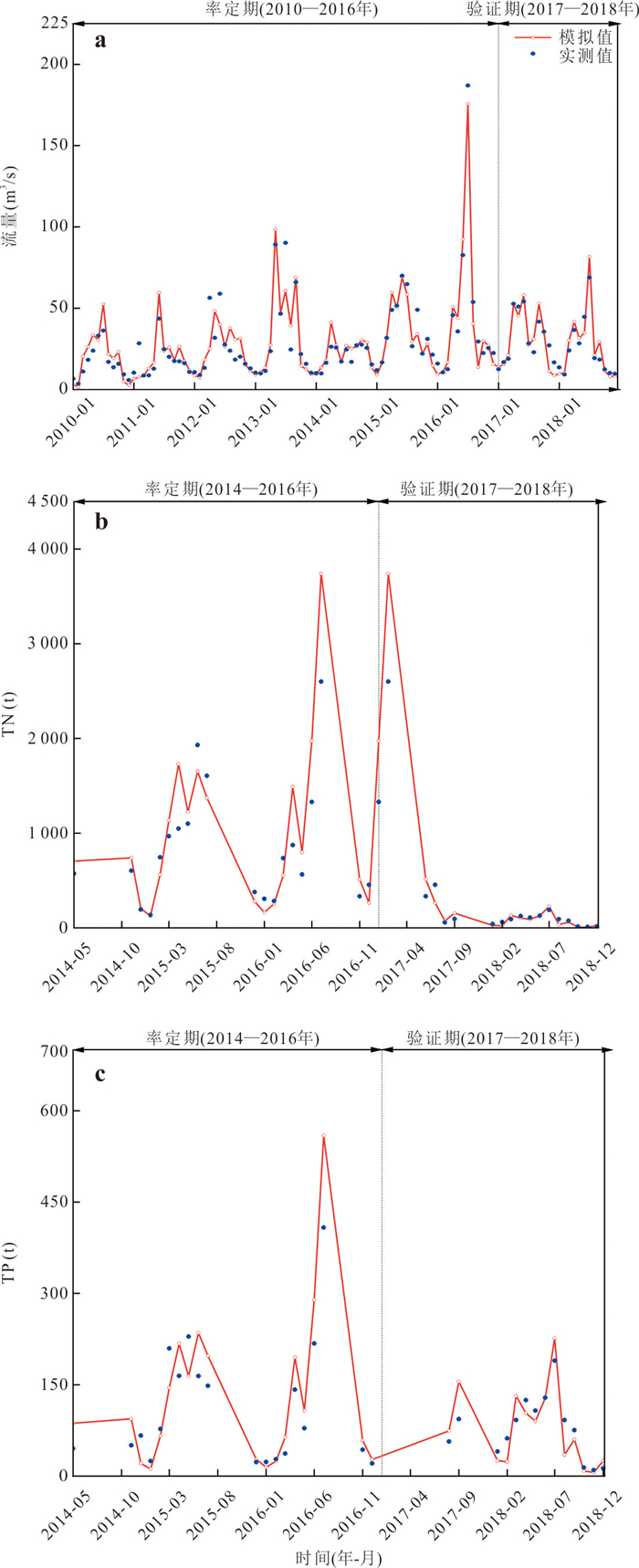
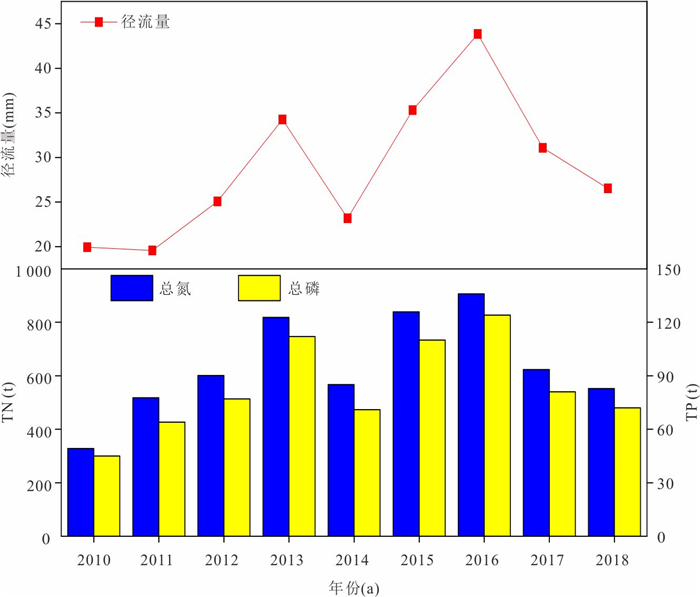
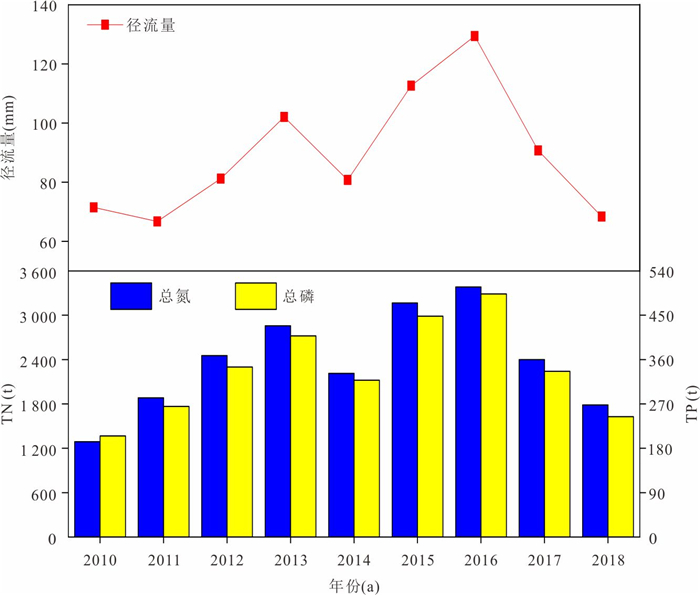
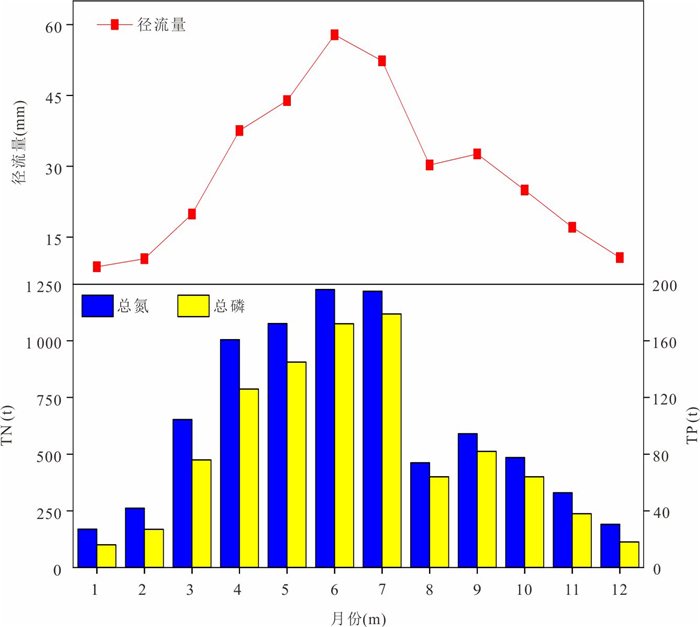
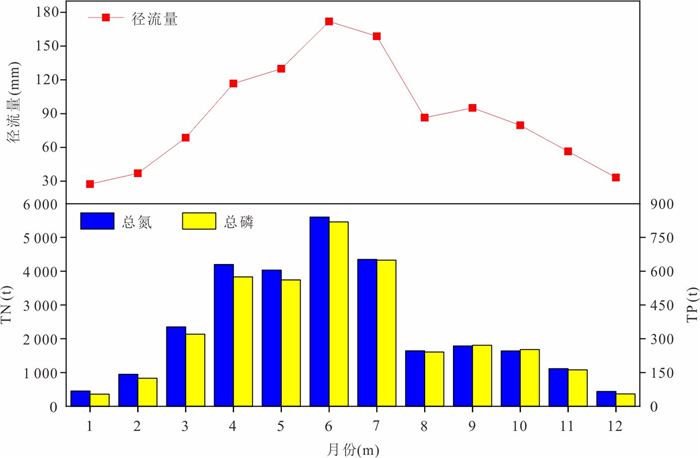
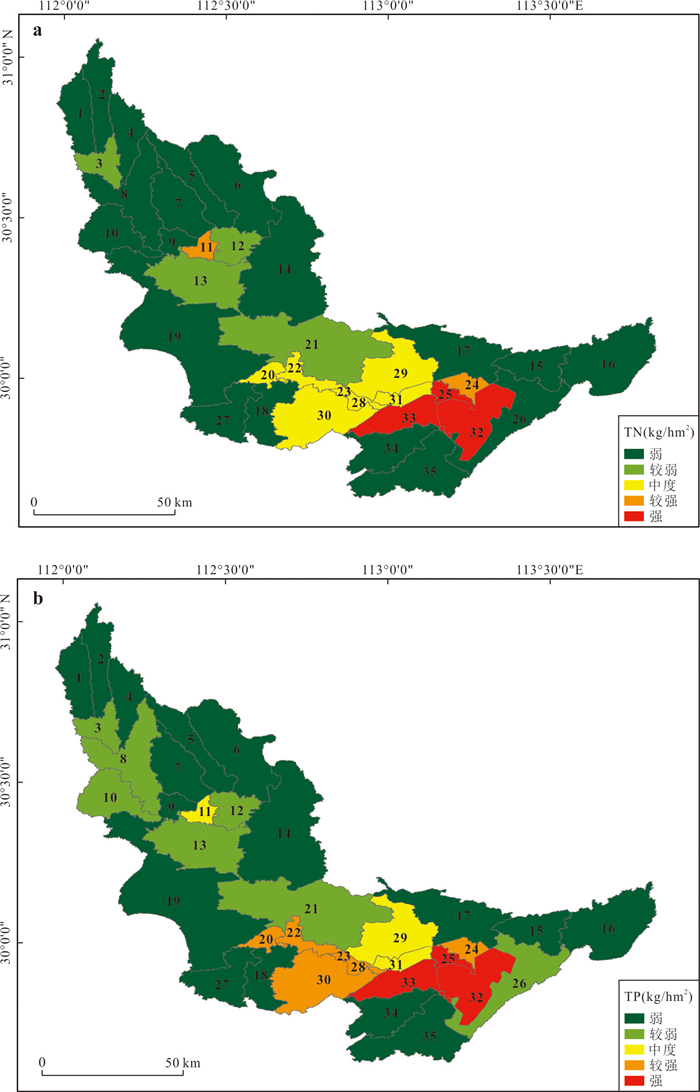
为精准识别四湖流域非点源氮磷污染的来源、时空分布特征及关键影响因素,为流域水污染防控提供科学依据,解决当前流域内湖泊水体富营养化突出的问题.以四湖流域为研究区,构建SWAT模型对流域内非点源氮磷污染的时空分布进行模拟.研究表明,该模型对流域内径流、总氮(TN)和总磷(TP)均具有较好的拟合效果;时间上,2010—2018年TN、TP负荷呈先升后降趋势,2016年达峰值,2017—2018年连续下降,年内呈“汛期高、非汛期低”的特征;空间上,氮磷负荷较高的子流域集中于流域中下游,分别为11、24、25、32、33号等子流域,耕地与水域是流域内氮磷产生的主要污染源.四湖流域氮磷污染负荷时空分布受径流、土地利用及降雨综合影响,时间上汛期及空间上湖泊、农业区是防控重点,可通过削减化肥使用、控制水产养殖规模、保护湿地等措施降低污染负荷.
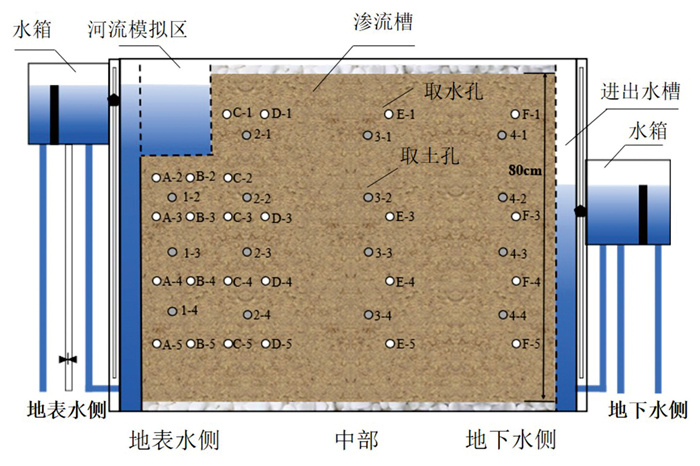
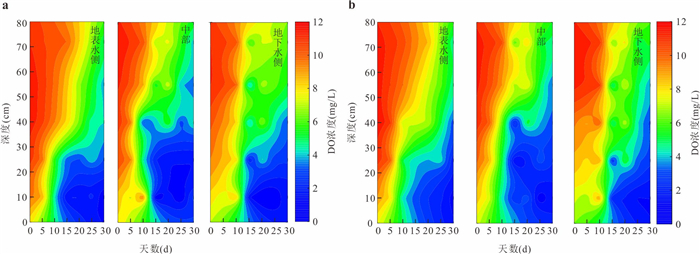
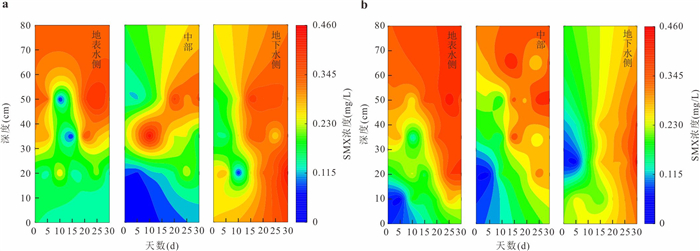
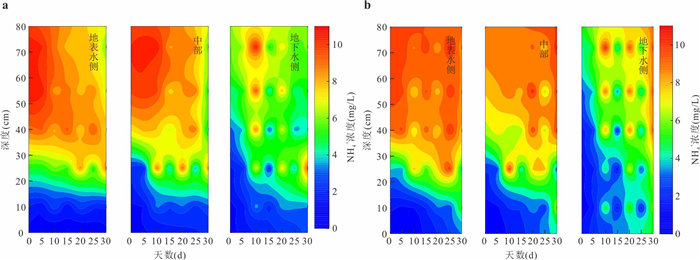
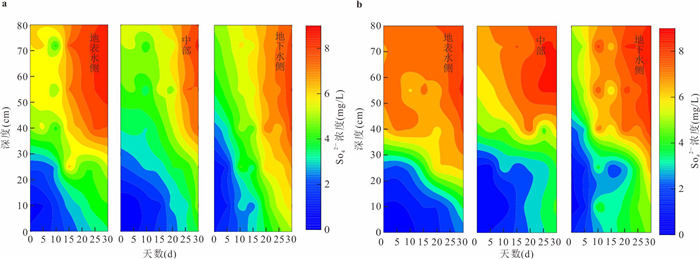
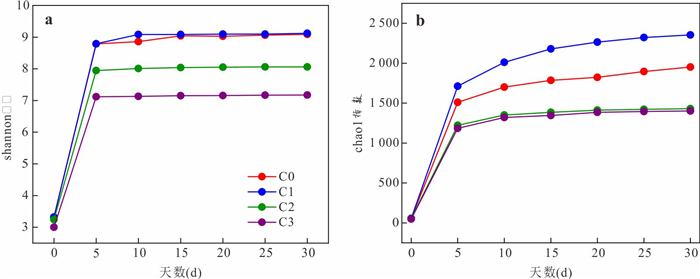
磺胺甲恶唑(sulfamethoxazole,SMX)作为一种广泛使用的抗生素,其在环境中的残留与检出频率持续增加,研究SMX在河流潜流带中的迁移转化行为对保障河流生态健康与水安全至关重要.本研究基于室内模拟实验,探讨了不同水力梯度下,地表水-地下水交互作用对潜流带沉积物中SMX迁移转化规律的影响.结果表明:地表水-地下水交互作用驱动着潜流带环境因子的动态变化,进而引起微生物多样性及群落结构的演替,最终影响SMX的迁移与转化行为.SMX在潜流带中的转化主要经由水解、脱硫化和生物降解途径实现,其主导衰减机制随交互作用时间的延长而转变.其中,变形菌门与厚壁菌门是参与SMX生物降解的优势菌群.此外,水力梯度对SMX的去除效率具有明显影响,在低水力梯度下,较小的水流流速更有利于SMX在沉积物中的滞留与降解,因而表现出更显著的去除效果.
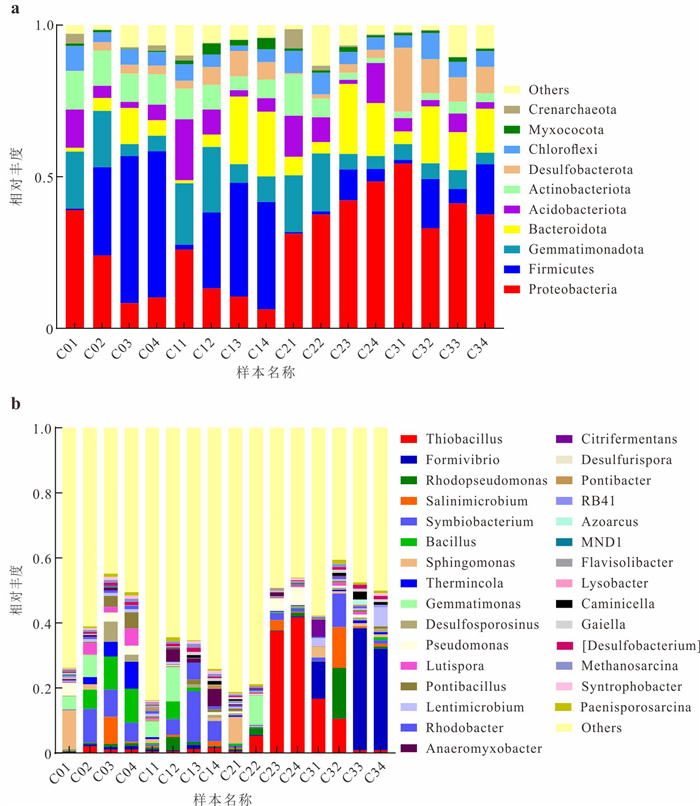
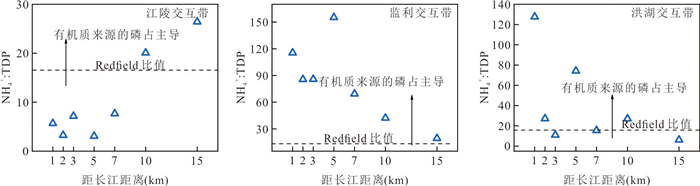
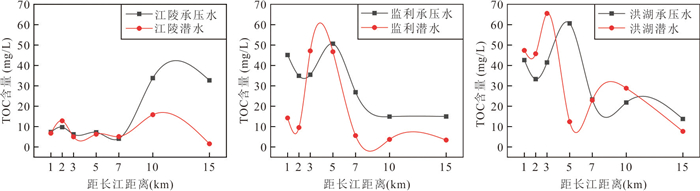
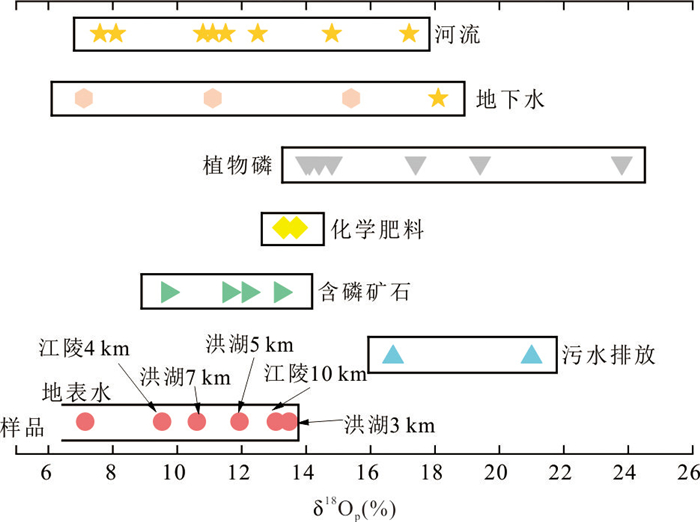
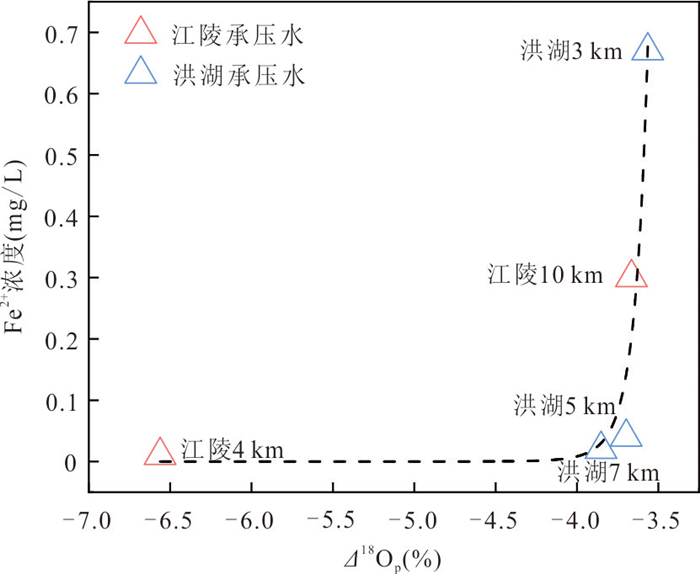
为了探究长江侧向交互带地下水中磷的富集特征与成因机制,以四湖流域内江陵、监利、洪湖3条侧向交互带为研究对象,开展了水化学和磷酸盐氧同位素(δ18Op)的分析.结果发现交互带地下水中普遍存在磷的显著富集区,潜水和承压水中富集位置存在差异.水化学分析显示监利断面磷富集主要受有机质矿化驱动,江陵断面与矿物溶解释放关系更为密切,而洪湖断面则受到了二者的共同调控.δ18Op证实了微生物磷循环参与诱导铁氧化物表面磷的还原溶解释放对承压水磷富集的重要作用.交互带磷富集的空间分异和主导机制受到水文过程调控,较强的水文过程促进有机质对磷富集的作用并使富集区更靠近长江.
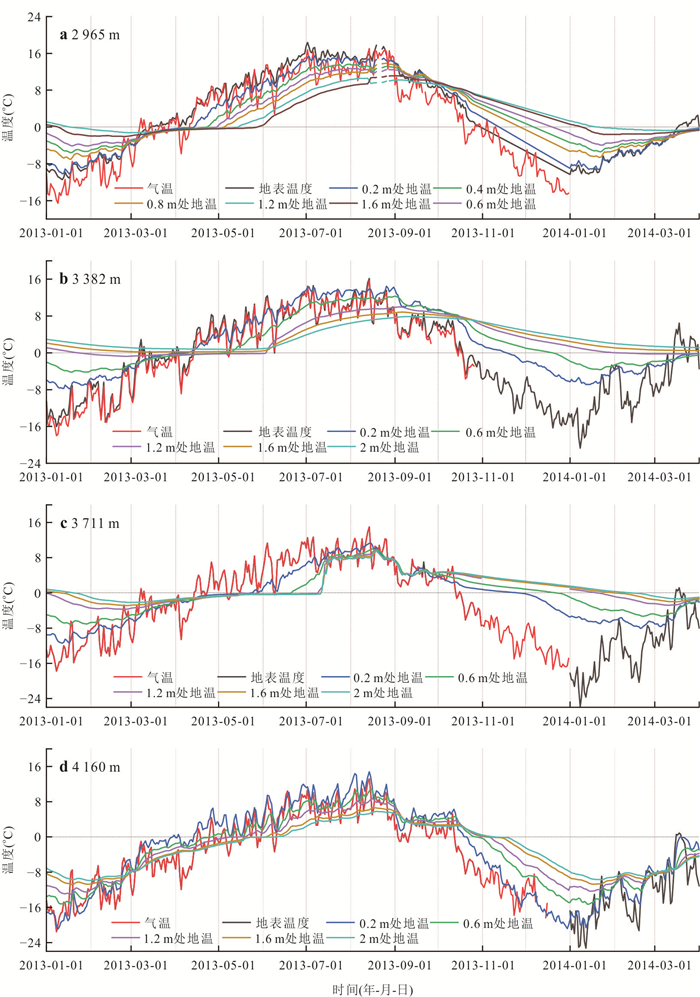
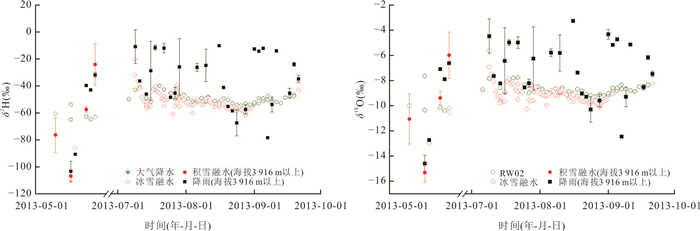
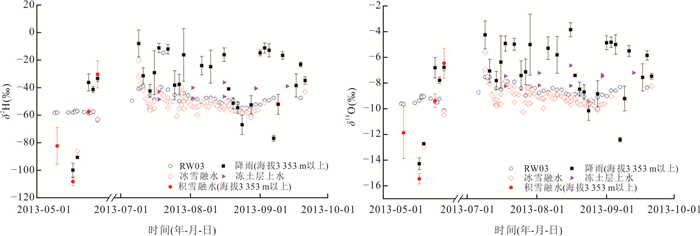
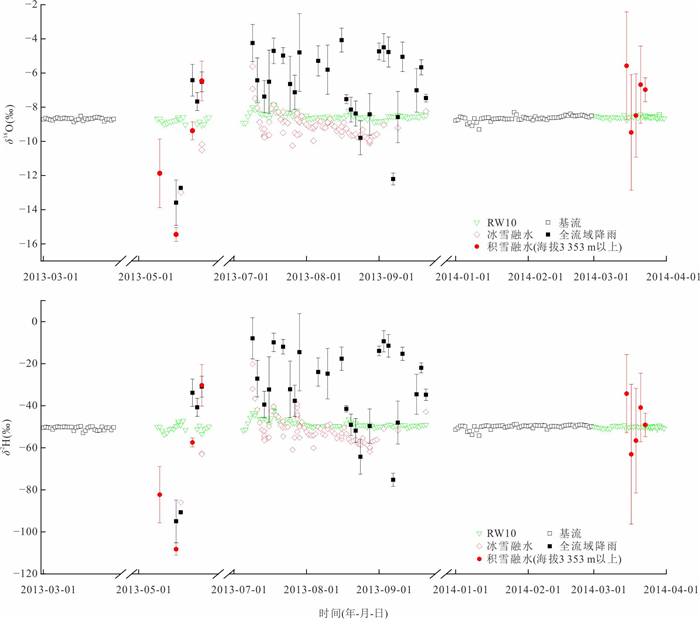
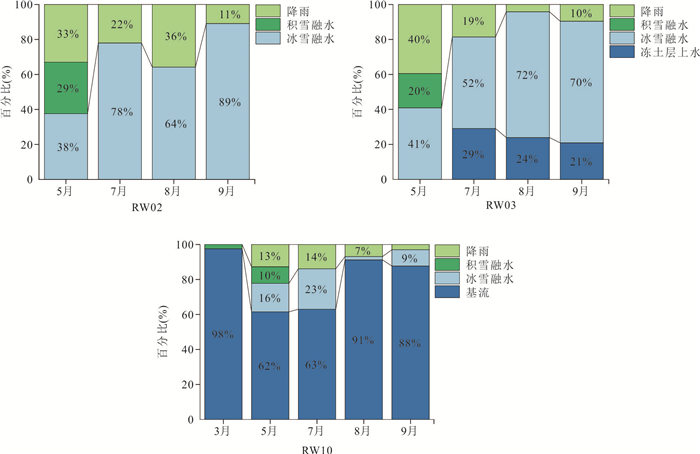
高寒山区是中下游地区的重要水源地,其径流过程受冻土等下垫面条件影响极为复杂. 相较于大尺度流域,小尺度流域更有助于揭示下垫面对水文过程的主导作用;然而,受高寒恶劣环境制约,观测资料稀缺,相关研究仍显不足. 为深入揭示小流域尺度下河道径流水分来源的时空分异规律,以黑河上游葫芦沟流域为例,结合水稳定同位素与水文气象观测,应用MixSIAR模型定量解析了多年冻岩区、多年冻土区和季节冻土区的河道径流组成.结果表明:3月季节冻土区径流以基流为主(98%),其余区域断流;5月,多年冻岩区与多年冻土区径流恢复,均以冰雪融水和积雪融水为主要水分来源,而季节冻土区仍以基流为主(62%);7月至9月,冰雪融水成为多年冻岩区和多年冻土区主要水分来源,季节冻土区基流仍为主要水分来源(63%以上).研究表明,气象要素是径流变化的主要驱动因素,而下垫面条件(如冻土分布与含水层特征)对水分来源组成具有关键调控作用. 研究成果深化了对高寒山区小流域水文过程机理的认识,可为寒区水资源管理提供理论依据.
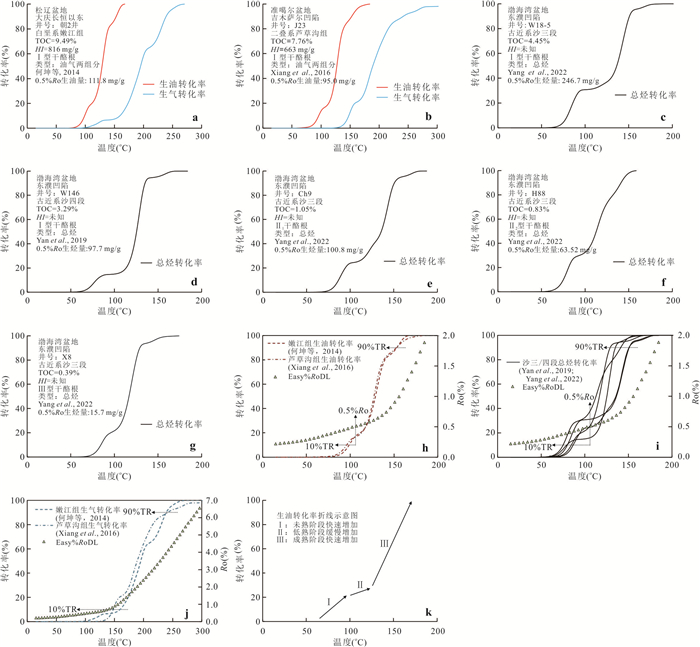
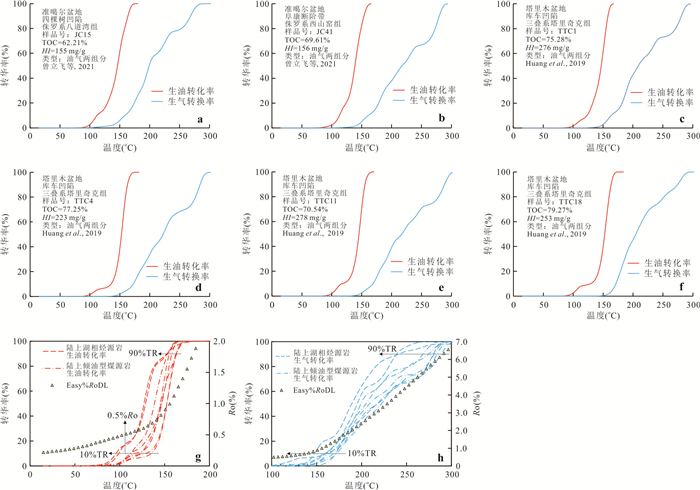
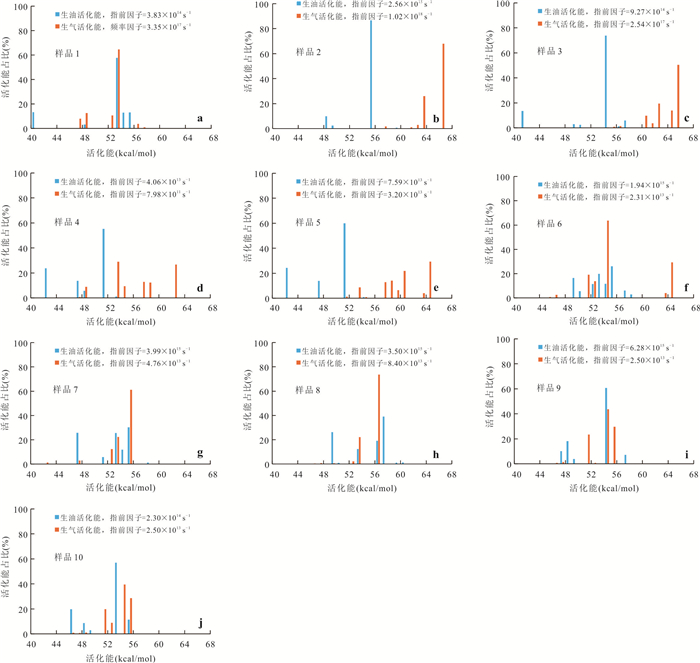
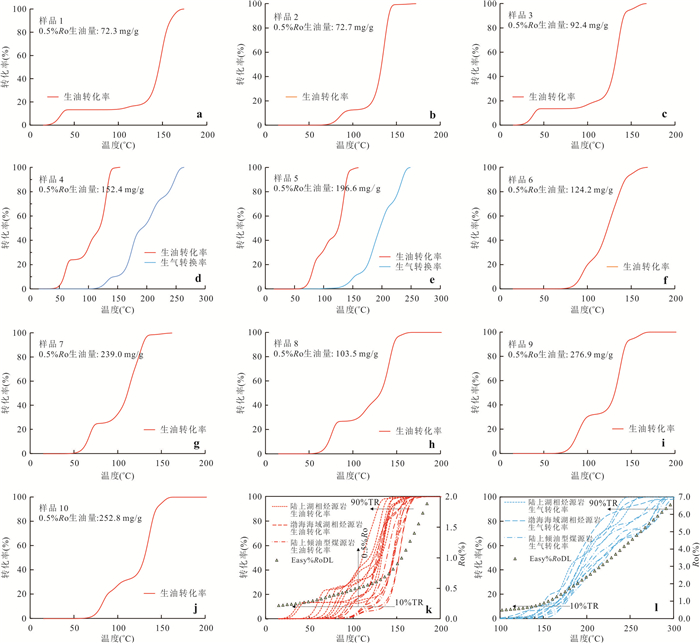
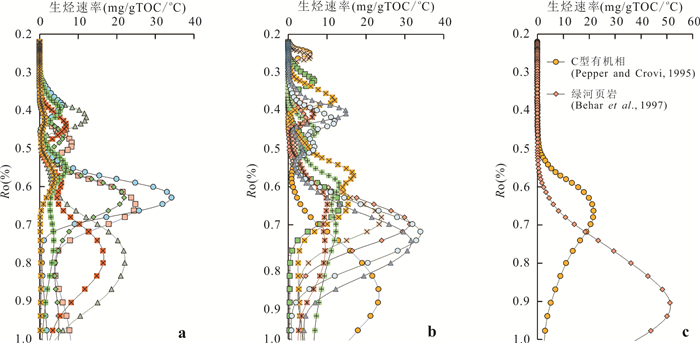
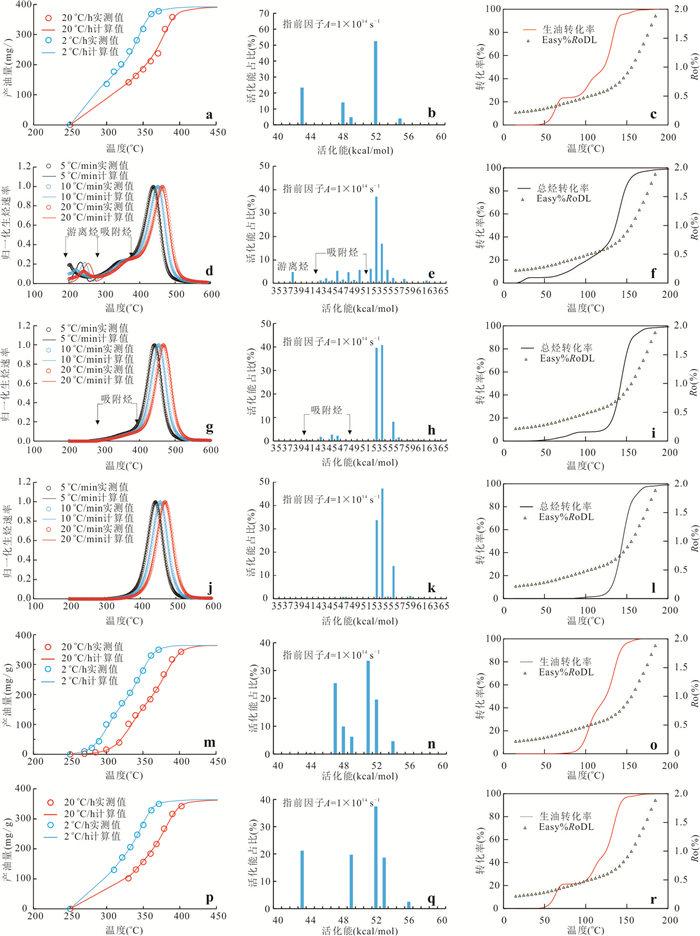
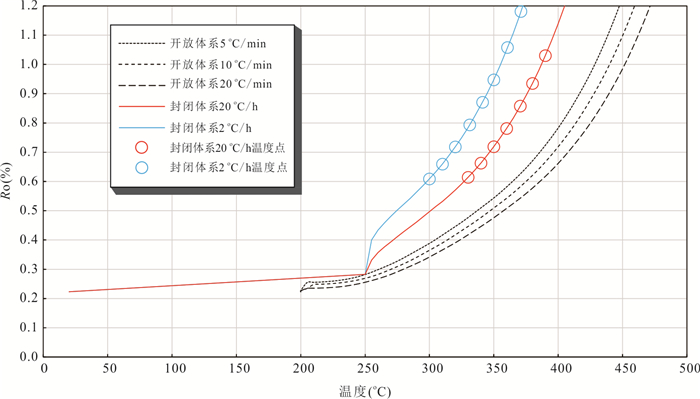
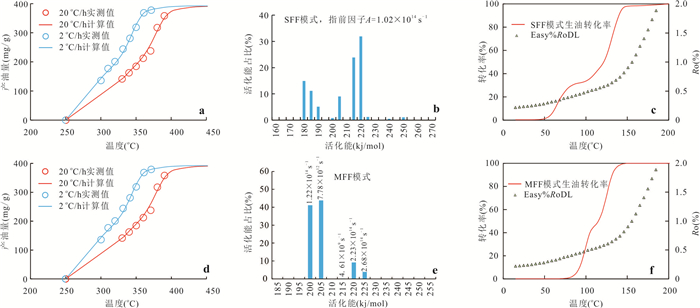
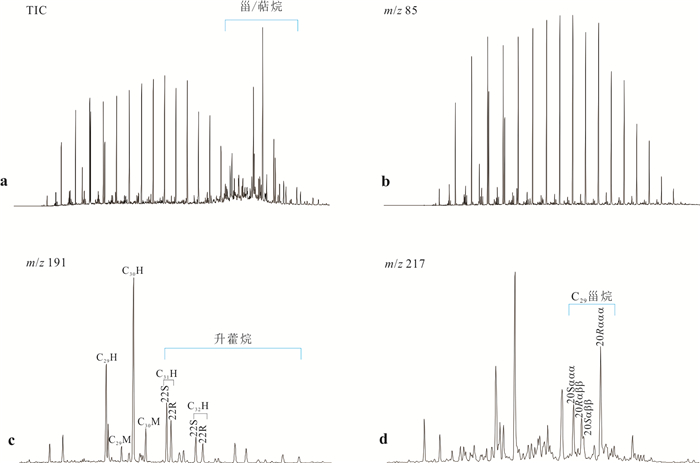
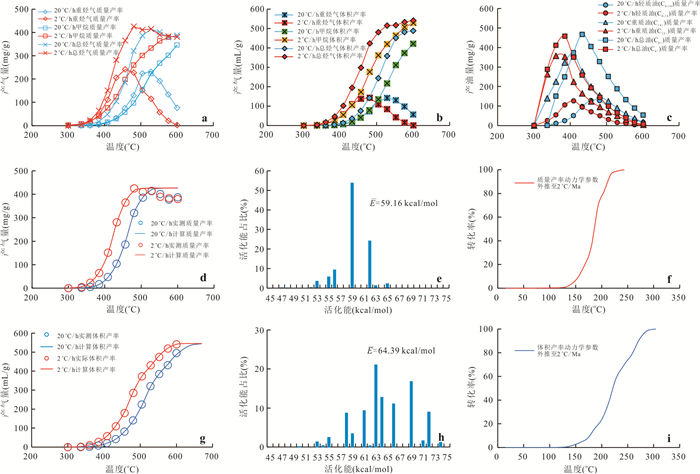
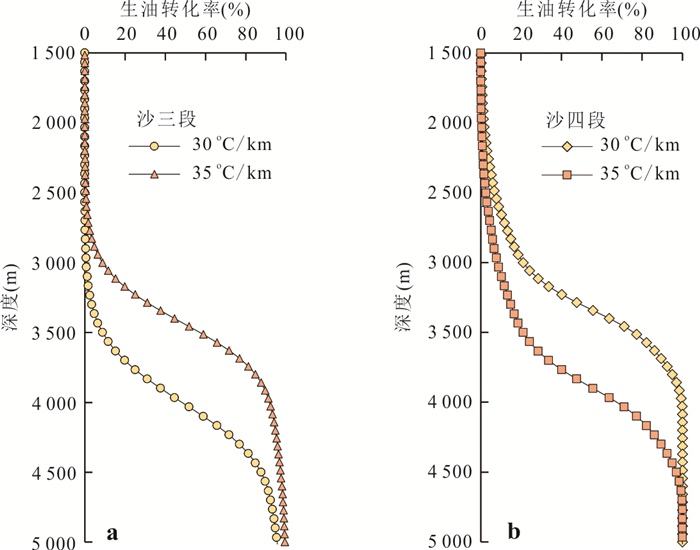
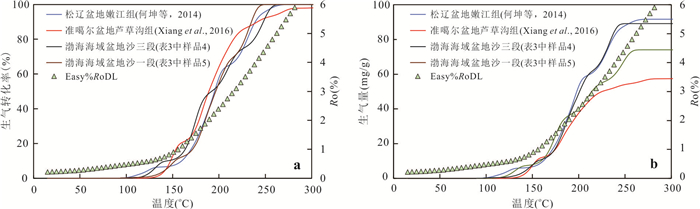
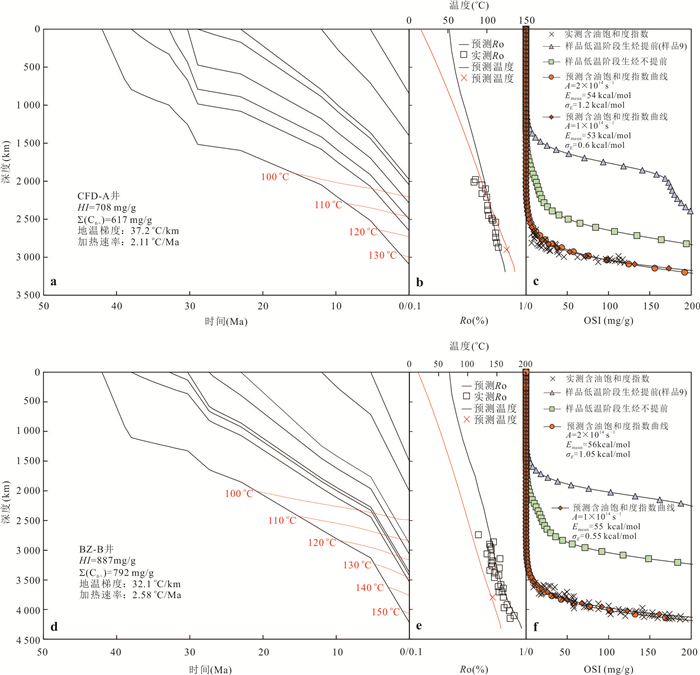
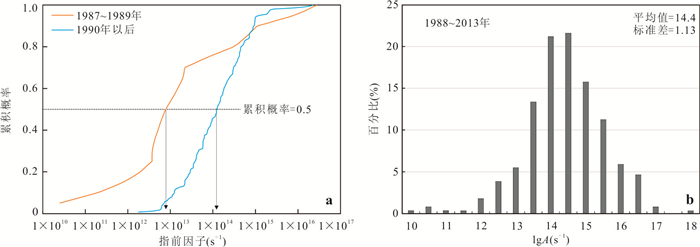
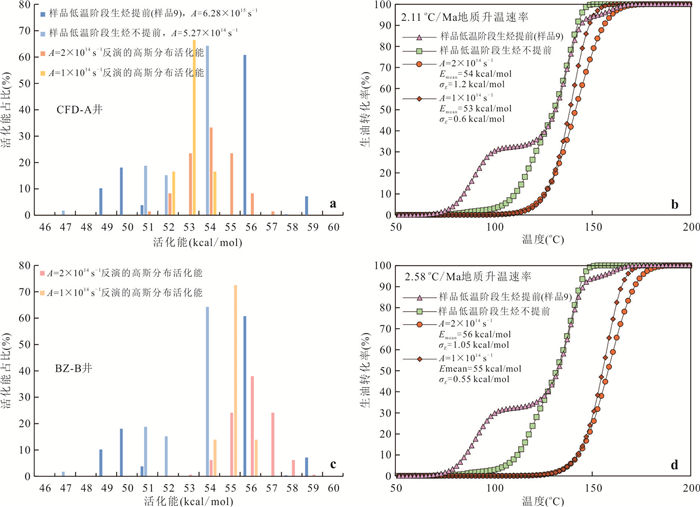
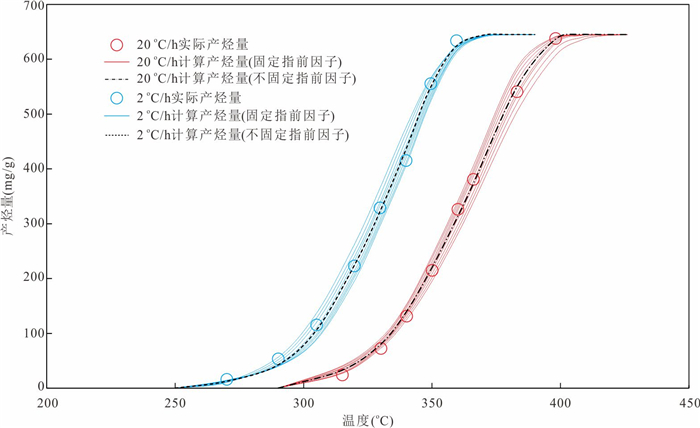
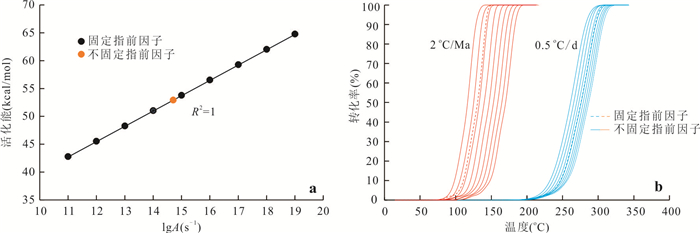
响应全国油气资源评价、成熟超级盆地精细勘探及页岩油研究领域的迫切需要,近年来黄金管热模拟已广泛应用于湖相烃源岩生烃动力学研究.为阐明湖相烃源岩金管生烃动力学参数外推至地质条件指导常规-非常规油气资源评价/勘探存在的技术风险,通过对渤海湾、松辽、塔里木和准噶尔等4个超级盆地23块湖相/倾油型煤源岩的生烃动力学参数进行地质条件外推结合湖相烃源岩金管/Rock-Eval热解平行实验,评述了金管体系生烃动力学参数标定、地质应用、校准和虚假补偿效应等问题.(1)生油动力学参数在地质应用时常出现低温阶段生油提前现象,与吸附烃残留、热解低温阶段缺少温度点、单指前因子模式标定动力学参数存在缺陷有关.(2)使用烃气质量/体积产率标定生气动力学参数时,需类比不同组分(C1、C2-5、C1-5、C6+)质量/体积产率曲线特征,以明确原油/重烃气裂解程度.(3)湖相烃源岩在生油窗生油转化率曲线陡倾,地温场差异显著影响生油量计算结果,石油资源评价需加强地温场研究;生气动力学参数应结合标定该参数时的气产率数据进行地质应用,但在过熟阶段高估了实际生气量;(4)使用含油饱和度指数(oil saturation index,OSI)-深度剖面校准生油动力学参数,可显著提升生油门限预测精度及游离烃(S1)含量评估的可靠性.(5)相同有机相源岩的不同动力学参数组合在实验室加热速率下可以预测相同反应速率(即虚假补偿效应),但在外推至地质条件/页岩油原位转化条件时会出现较大偏差,应加强与地质资料的对比和校准,尝试不固定/固定指前因子标定多组动力学参数.从油气勘探应用角度,未来应重视金管体系的初次裂解组分/原油裂解组分计量及其相关动力学参数表征方面的攻关探索.
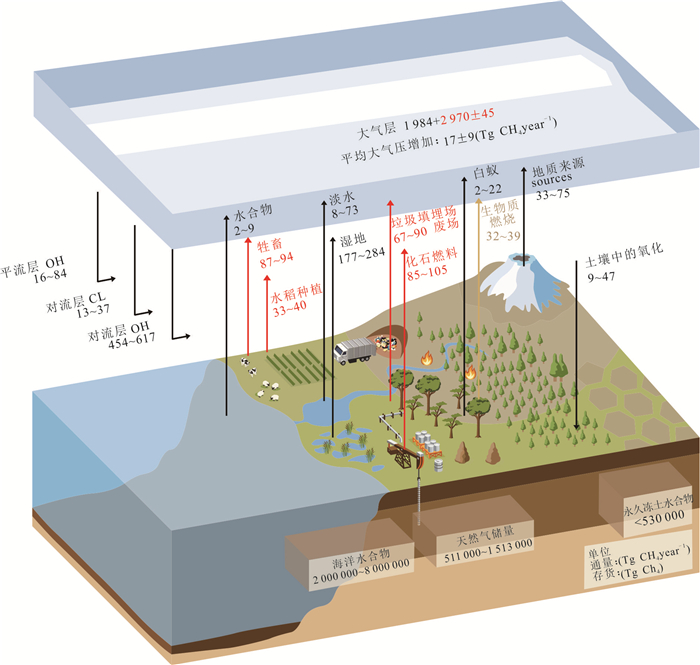
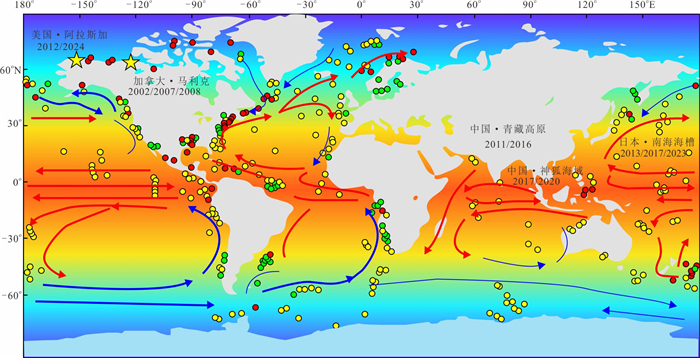
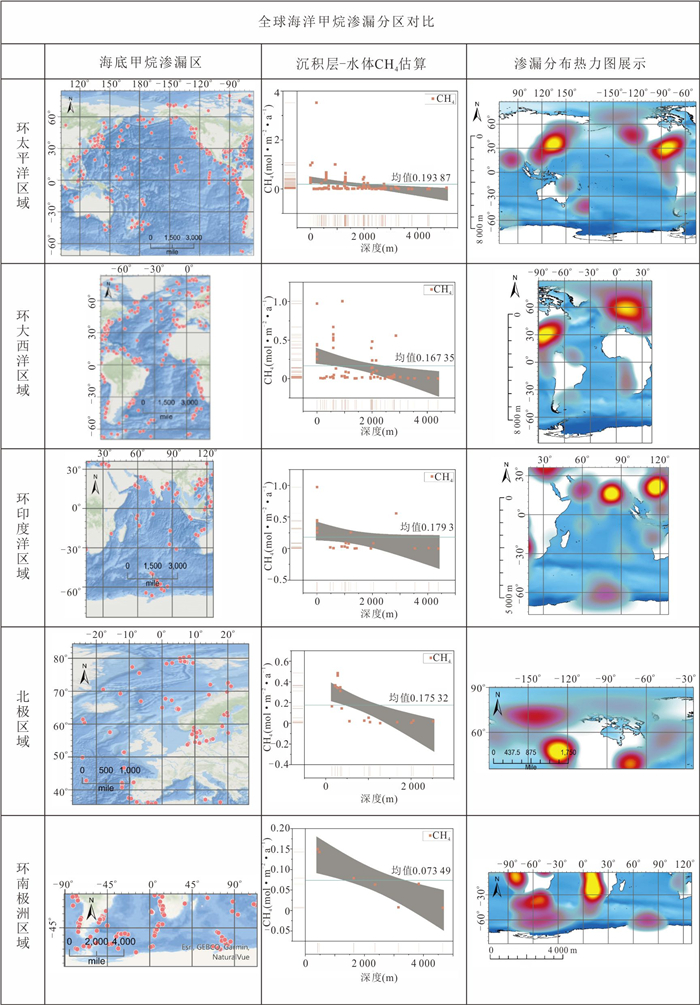
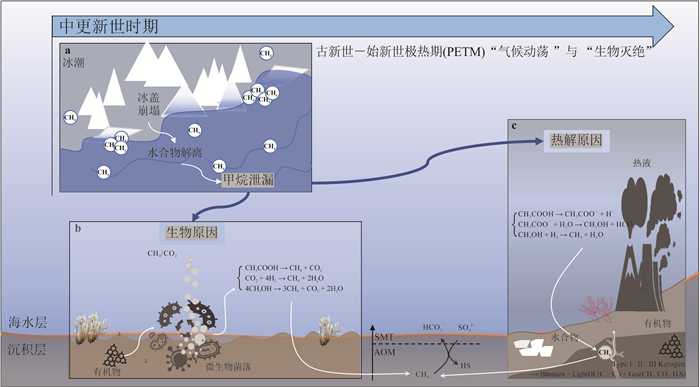
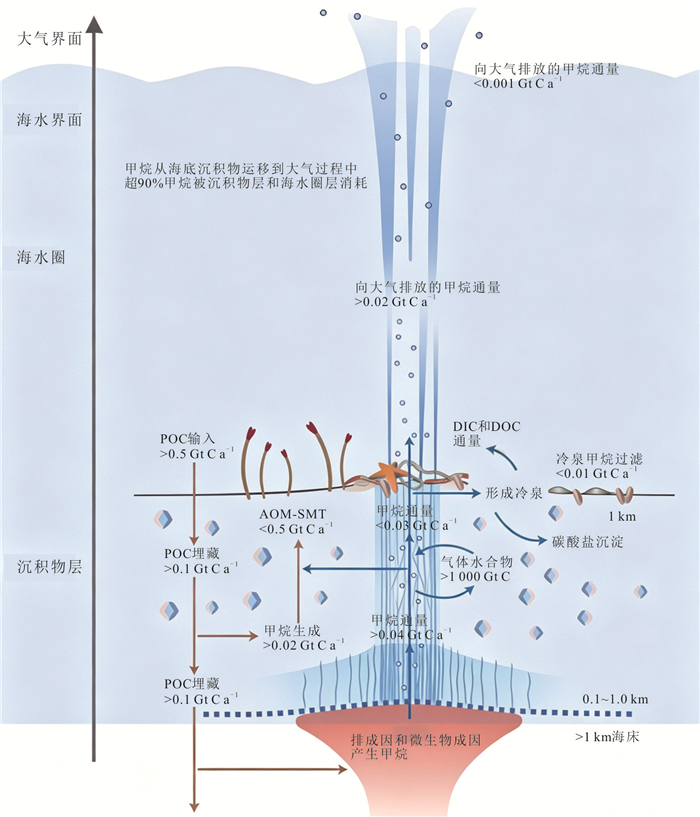
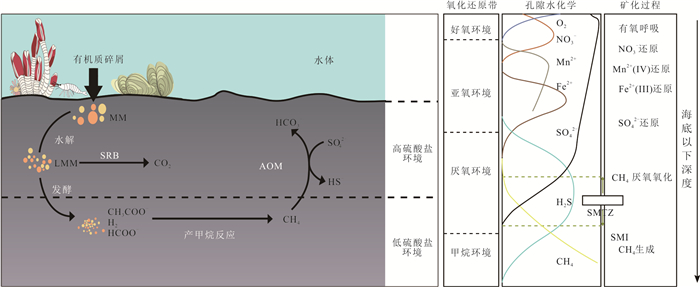
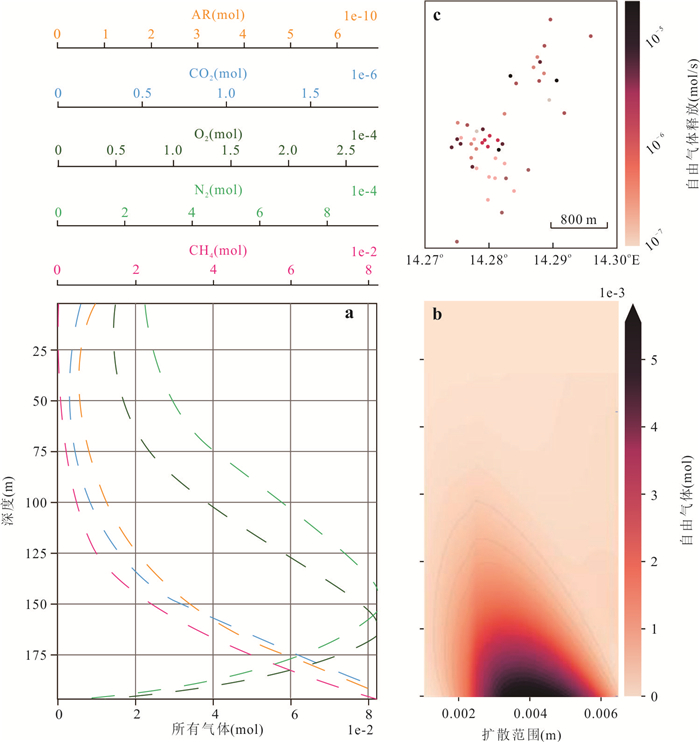
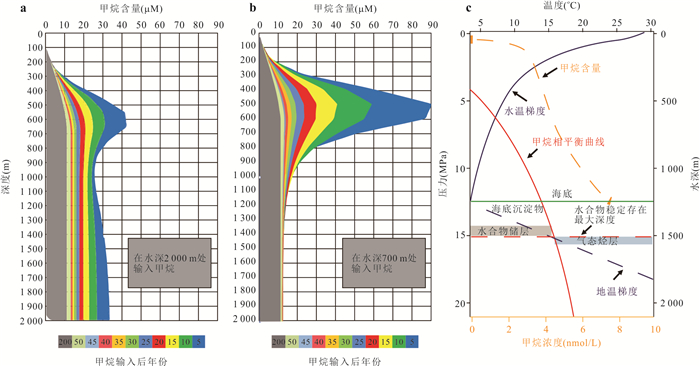
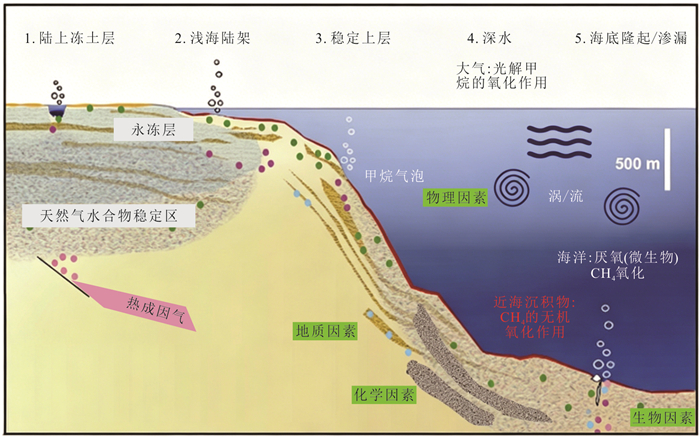
甲烷作为强效温室气体,其单分子温室效应在百年尺度上是二氧化碳的30倍,而海洋甲烷储量占全球总储量的95%,甲烷源汇过程直接影响全球气候变化.本文通过文献调研和数据分析方法,系统梳理了全球海洋甲烷渗漏的空间分布格局与运移扩散机理,并结合南海、墨西哥湾等典型案例区实测数据定量评估环境效应.结果显示全球甲烷渗漏呈显著空间差异,环太平洋海域渗漏最为活跃,北极与大西洋沿岸次之,环南极洲海域最低.这种分布格局主要由板块构造活动、水合物稳定带条件以及沉积有机质供给共同控制.北极等高纬度地区的实际渗漏活跃度可能被低估,这些地方是海洋甲烷进入大气的主要来源.从全球来看约70%~90%的海底渗漏甲烷被微生物氧化消耗,但仍有1.5%~4.0%直接进入大气,年贡献量6~12 Tg.海底甲烷渗漏通过水体运移扩散、生态重构和温室气体排放对全球环境产生显著影响.应加强动态监测及甲烷负排放技术研发,服务“双碳”目标与全球气候治理.

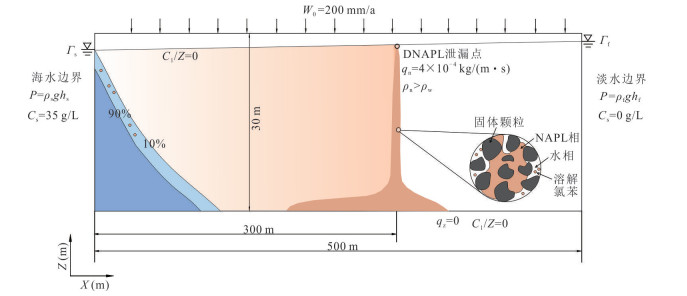
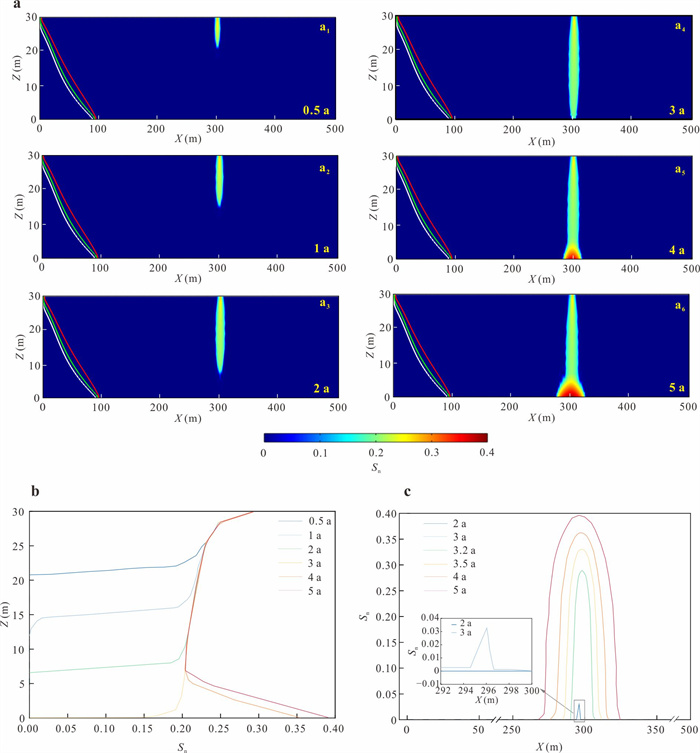
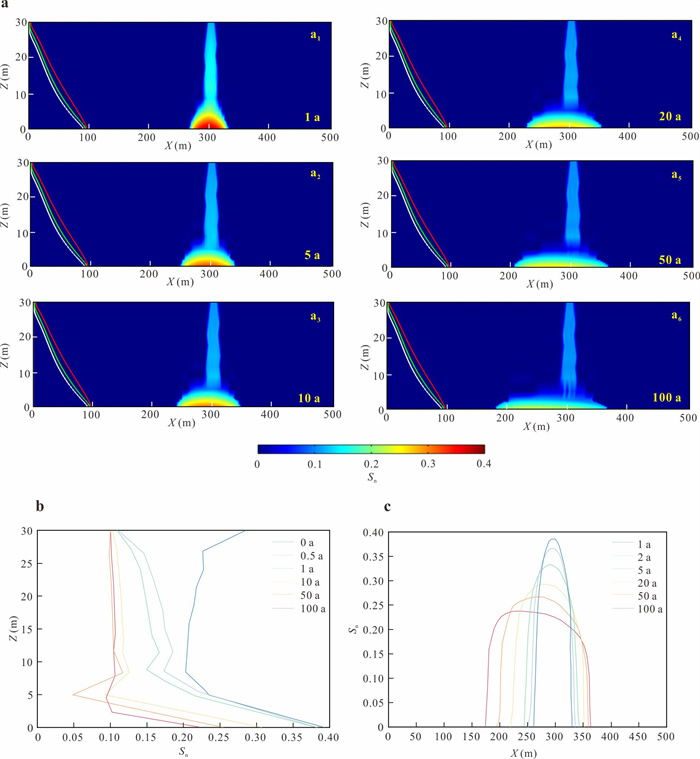
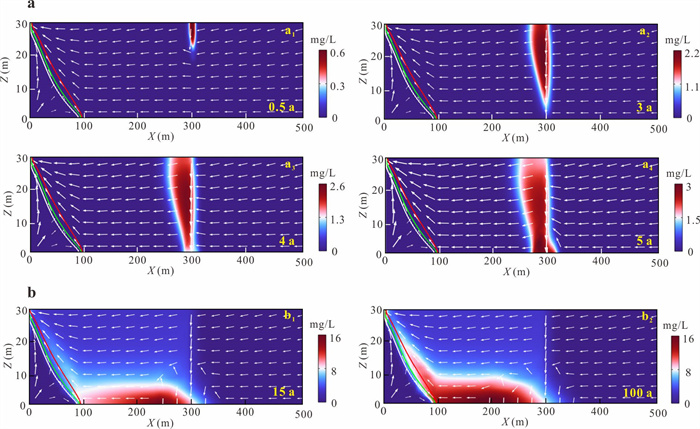
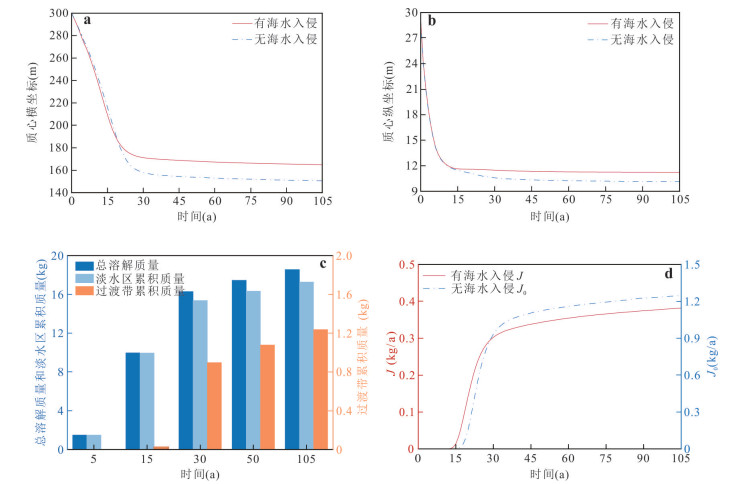
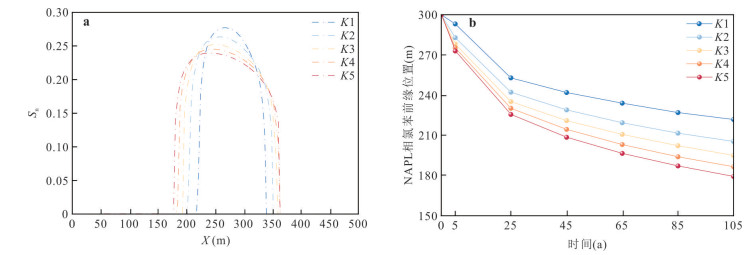
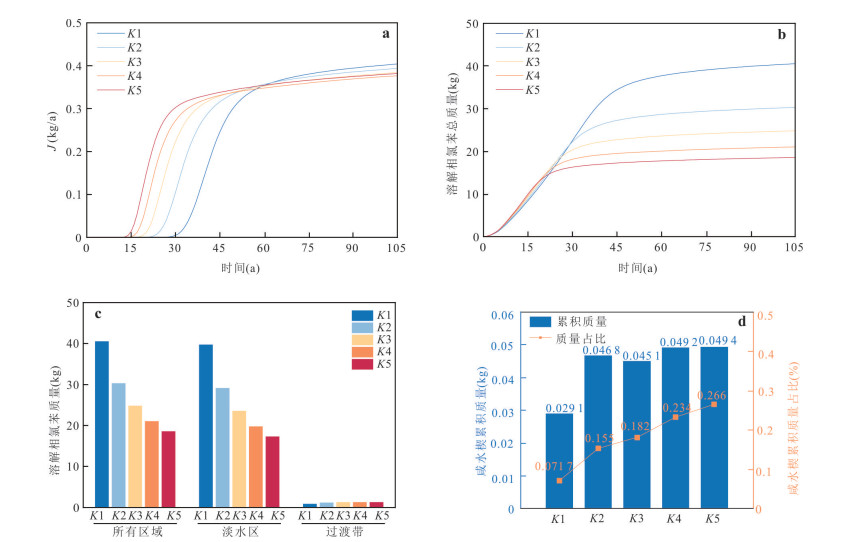
为揭示海水入侵所驱动的变密度流场对重质非水相液体(dense non-aqueous phase liquids,DNAPL)多相运移路径与相间质量交换的调控机制,本研究以氯苯为例构建变密度流-多相流-溶质运移耦合数值模型,系统模拟其入渗、再分布及溶解羽演化过程.研究结果表明:(1)NAPL相氯苯在重力主导下垂直入渗并在隔水底板形成非对称污染池;(2)咸水楔显著改变溶解相氯苯的运移路径,密度梯度驱动其沿咸淡水界面爬升,并在咸淡水过渡带积聚,且排海通量峰值较无海水入侵情景降低62%;(3)渗透系数K的增大加速NAPL相和溶解相氯苯向海洋边界迁移,同时强化溶解相在咸淡水过渡带的累积.本研究阐明了咸淡水过渡带对DNAPL迁移的截留机制,证实该区域是滨海地下水环境风险评估中不可忽视的长期次生污染源.
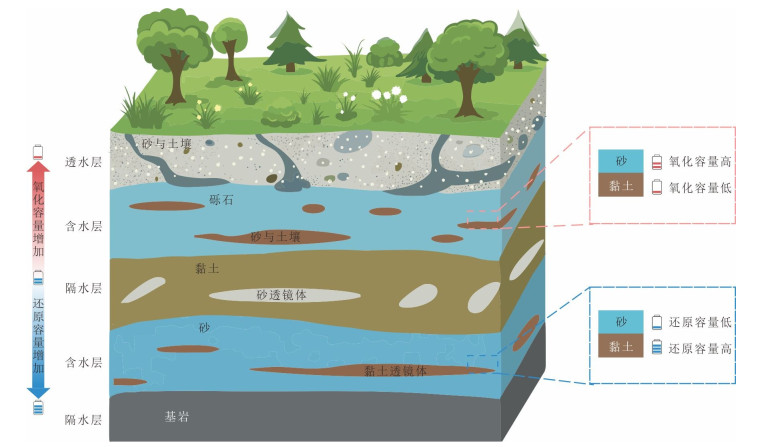
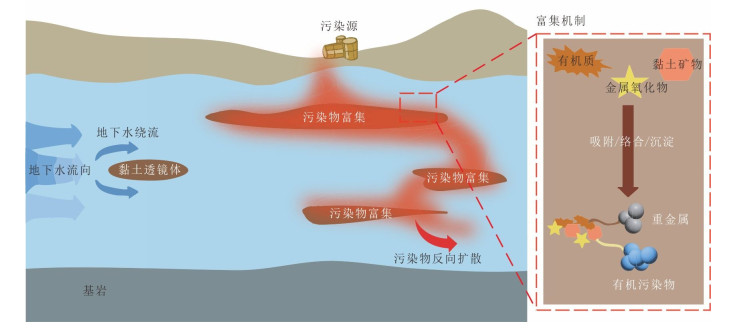
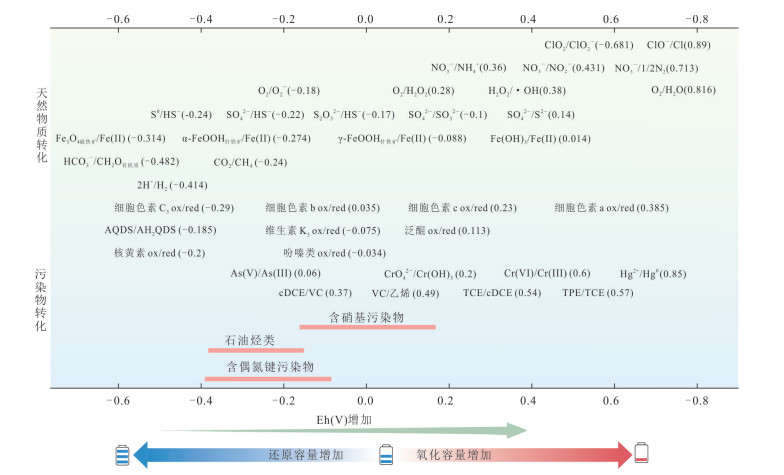
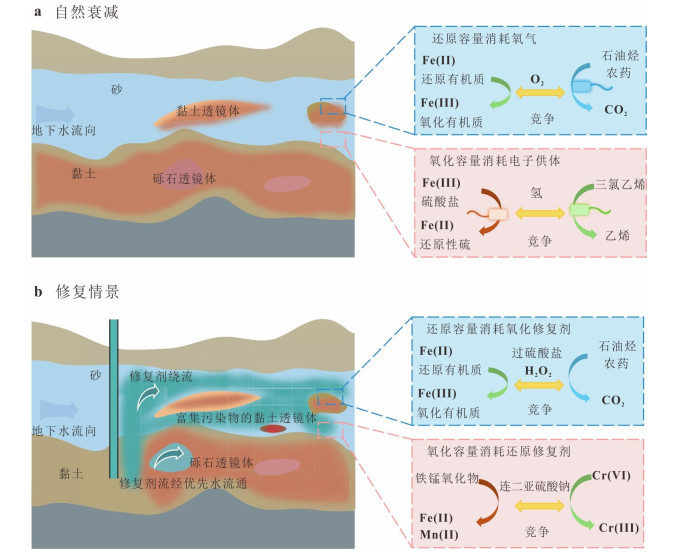
孔隙含水层非均质性是制约污染场地地下水修复的核心因素.阐述了结构与氧化还原两种非均质性的概念,深入分析了两种非均质性对污染物和修复剂迁移转化的影响机制.结构非均质主要影响污染物迁移和修复剂传输扩散过程,含水介质渗透性差异通常导致低渗区成为修复剂难以入渗的修复盲区,在修复后期因反向扩散出现污染物浓度反弹.以氧化还原容量差异表征的氧化还原非均质性,主要通过参与电子转移过程影响污染物转化和修复剂消耗,因此选择修复技术和设计参数时需特别考虑氧化还原容量的影响.最后针对非均质含水层修复中的关键挑战,在总结应对措施的基础上提出了未来的研究方向.
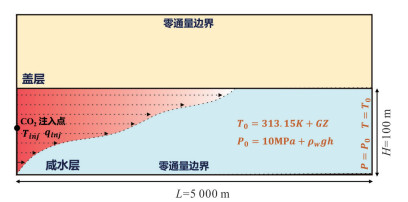
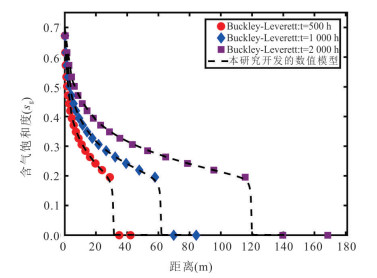
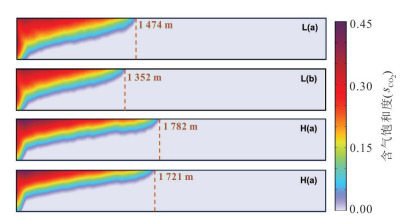
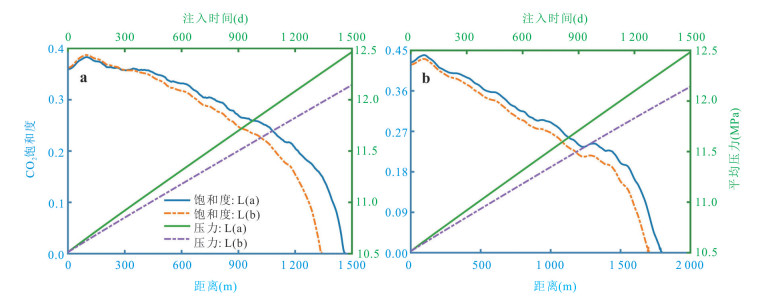
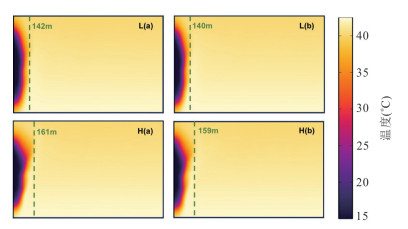
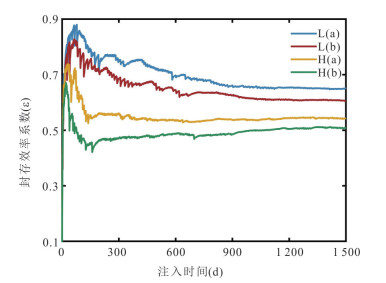
深入理解储层非均质性及多场耦合效应对于准确评估封存过程中CO2运移、转化及封存机制具有重要意义.本文综合考虑了气-水两相流动机制、储层孔渗结构的动态演化及非等温条件下温度对CO2物性的影响,构建了热-水-气-力耦合模型,旨在探讨非均质咸水层中CO2的迁移动态与封存效率.模拟结果表明,储层非均质性对平均孔隙压力的积聚具有显著影响,低孔隙度地层中孔隙压力增幅约为1.96 MPa,而较高孔隙度地层中仅约为1.64 MPa,进而影响了CO2的物性参数与运移路径.同时,热锋的最大迁移距离仅约为161 m,而CO2羽流的最大横向迁移距离可达1 782 m.在CO2注入过程中,储层渗透率和孔隙度分别以1.01~1.13的比率和2.10%~12.8%的幅度变化,且低渗储层的孔渗结构对压力扰动更为敏感.在低渗非均质储层中,CO2最大封存效率系数约为0.88,显著高于高渗储层,证明了在此类地层中保持低于岩石破裂压力的注气速率有助于提升CO2的有效封存能力与长期稳定性.



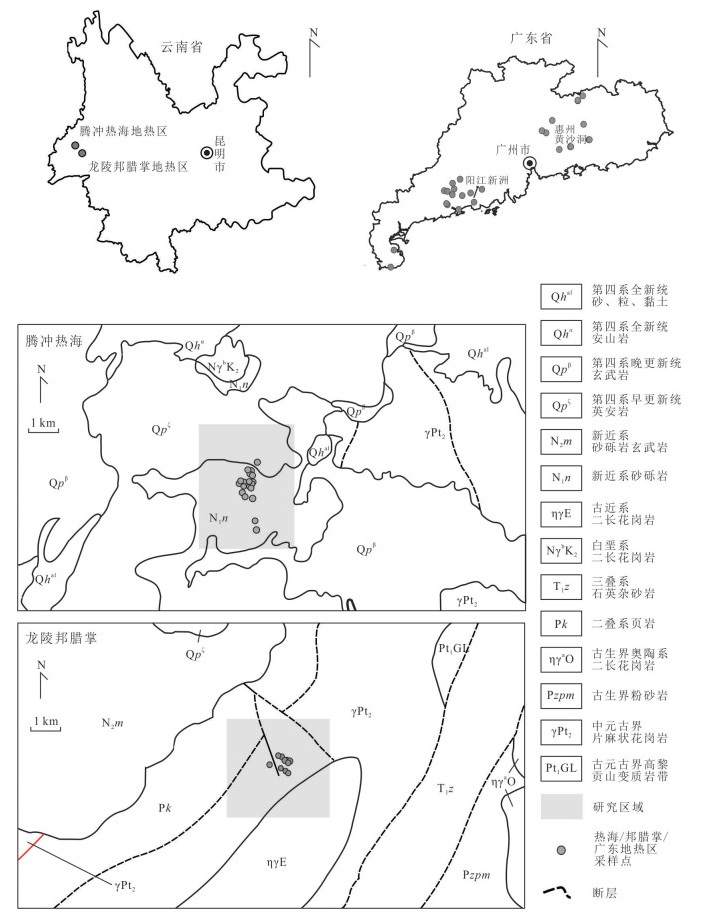
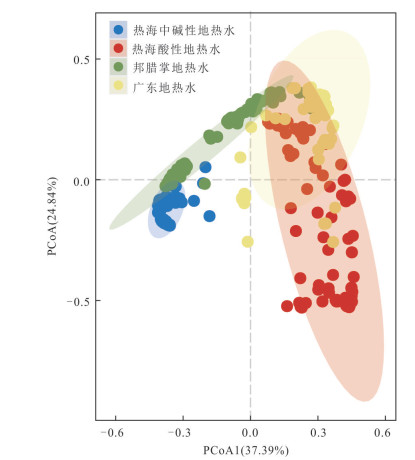
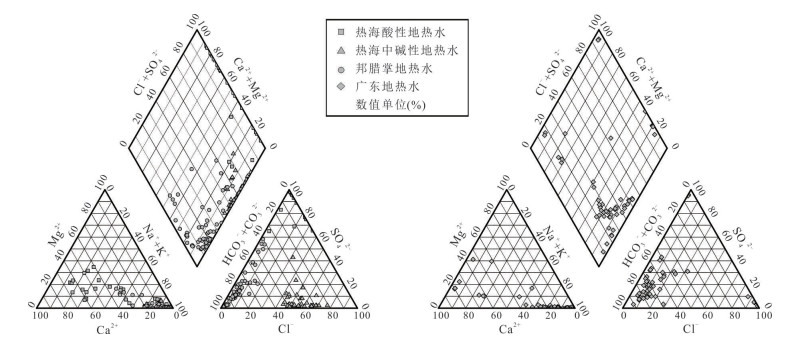
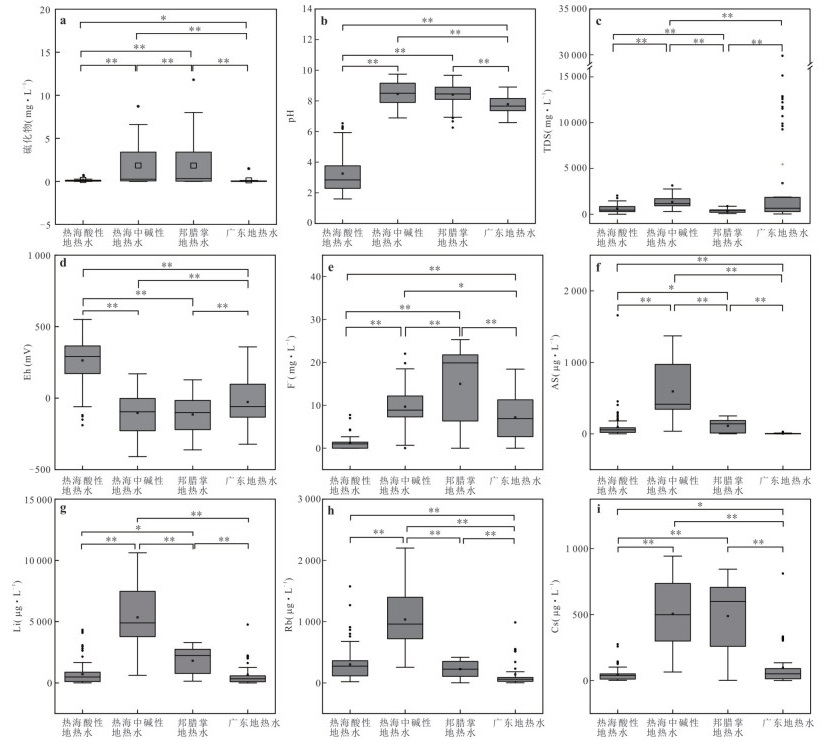
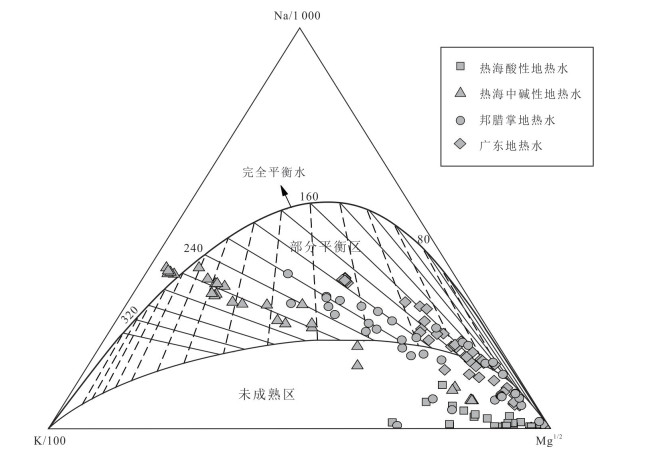
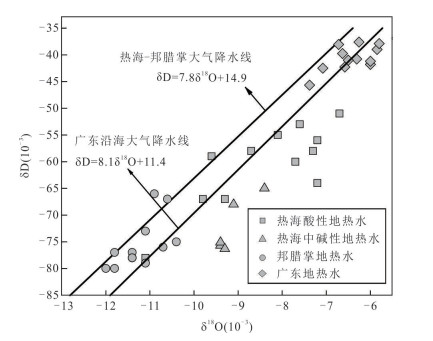
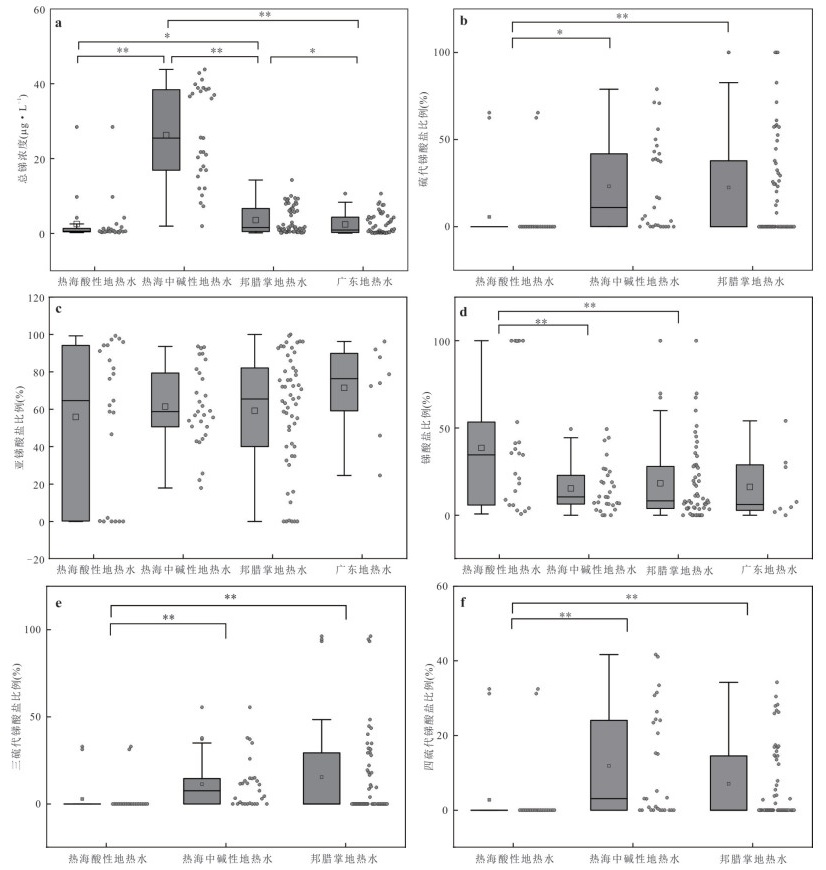
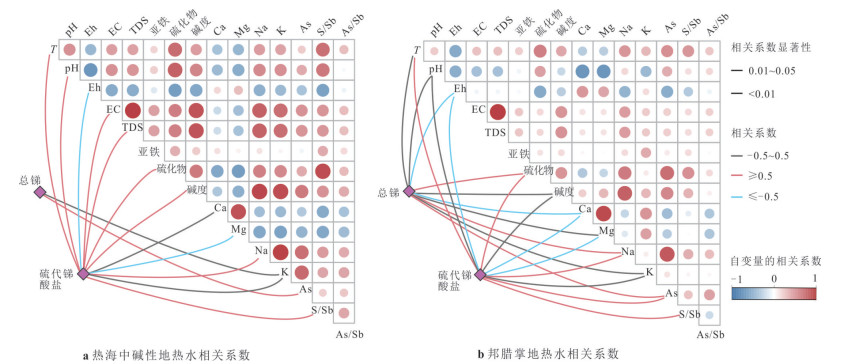
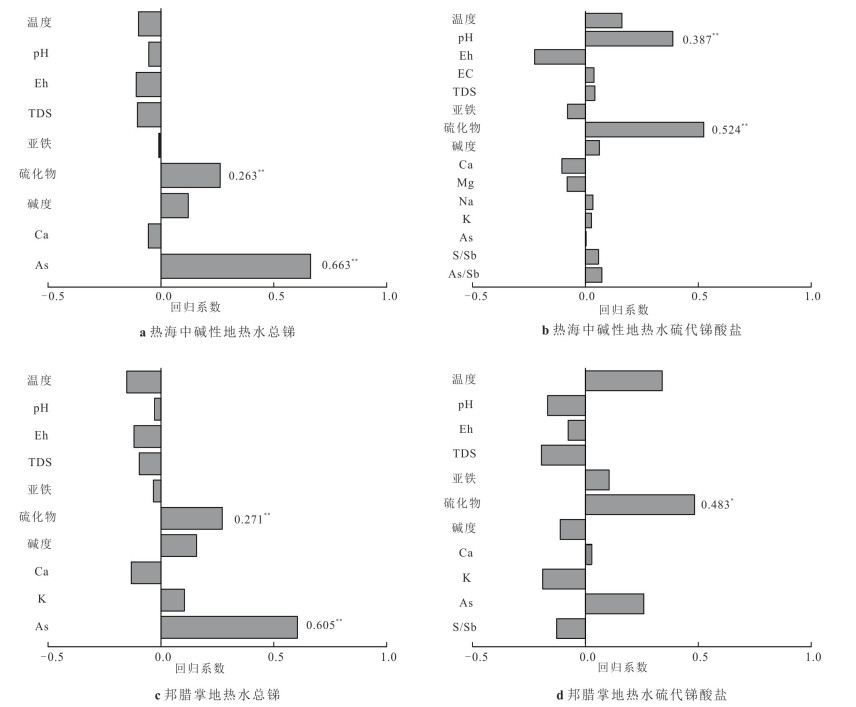
为理解不同类型地热水中总锑及锑形态的分布特征、主控因素及其指示意义,选择云南腾冲热海、龙陵邦腊掌和广东诸地热区,系统对比了存在壳内岩浆囊且接受岩浆流体输入、存在壳内岩浆囊但未接受岩浆流体输入、不存在壳内岩浆囊3类地热系统中地热水的总锑和各锑形态含量并分析了其主控因素.结果表明:总锑含量与地热水成因密切相关;而硫化物的富集及偏高的pH是硫代锑酸盐形成的关键条件.总体来看,地热水中锑形态分布受控于其地球化学环境,对地热系统成因有一定指示意义:未形成硫代锑酸盐的地热水几乎不可能接受岩浆流体直接输入,但无论有无岩浆流体输入,地热水中均可能因富集硫化物而形成硫代锑酸盐.
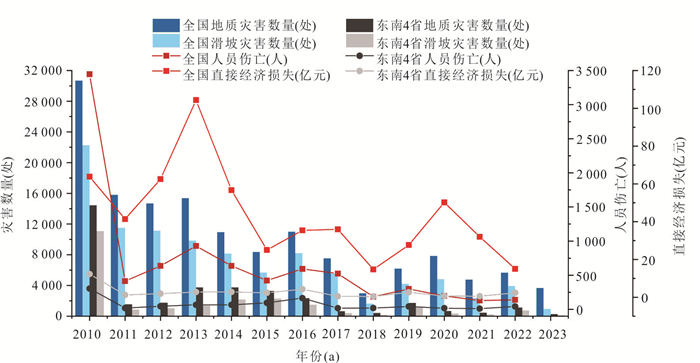
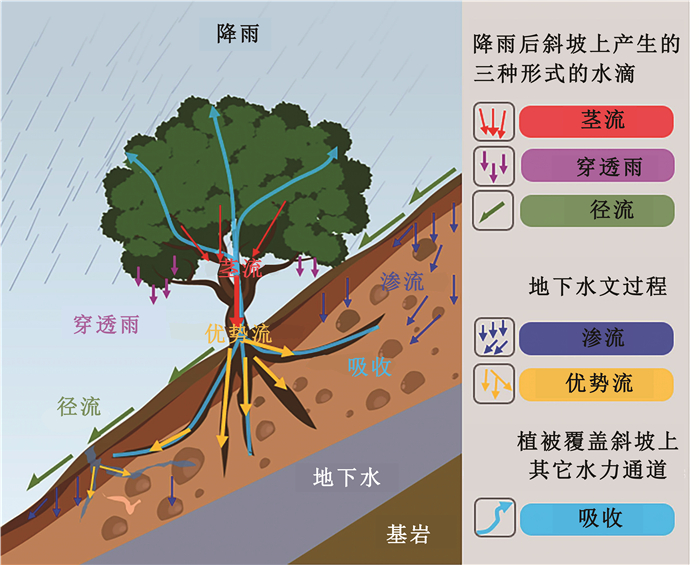
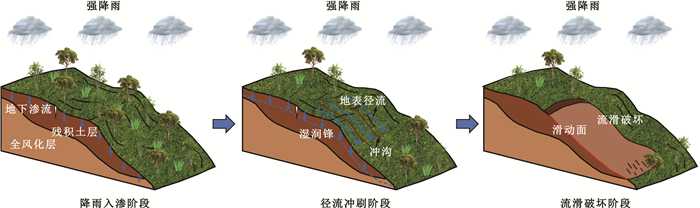
东南地区是我国降雨型群发滑坡的高发区,其孕育过程受地质、气象、水文、生态与人类活动等多因素综合控制,具有明显的多尺度效应.本文系统回顾了多因素耦合作用下东南降雨型群发滑坡的多尺度孕育机制研究进展,重点分析了地质条件、气象水文、生态环境和人类活动等因素的单独及协同作用机制,阐述了从单体尺度到流域尺度滑坡孕育过程的差异与联系,并总结了现场监测、物理模型试验、数值模拟和人工智能数据驱动等研究方法的应用现状.研究表明,多因素耦合机制与跨尺度联动是理解群发滑坡孕育规律的关键,但目前仍存在多因素动态耦合机制不清、模型跨尺度衔接不足等挑战.未来应加强群发滑坡多因素互馈机制和协同演化物理力学过程研究,推动构建多尺度孕育模型,提升区域滑坡灾害预警与防控能力.

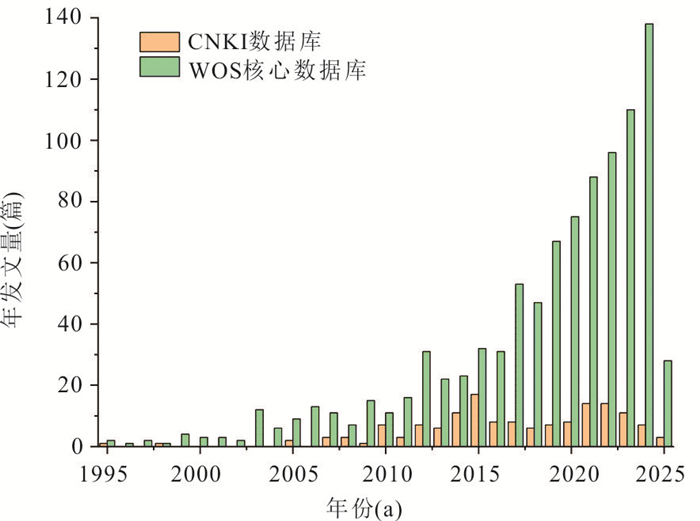
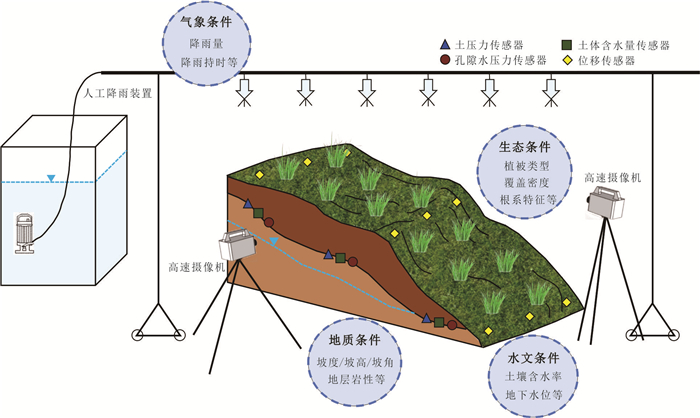
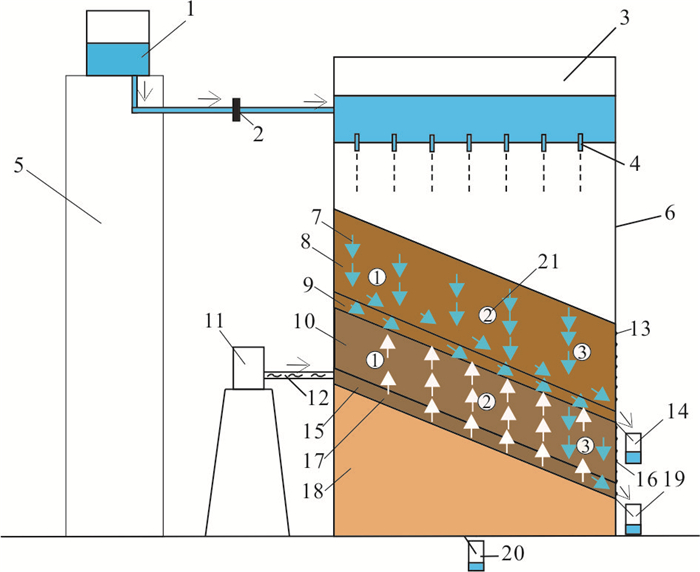
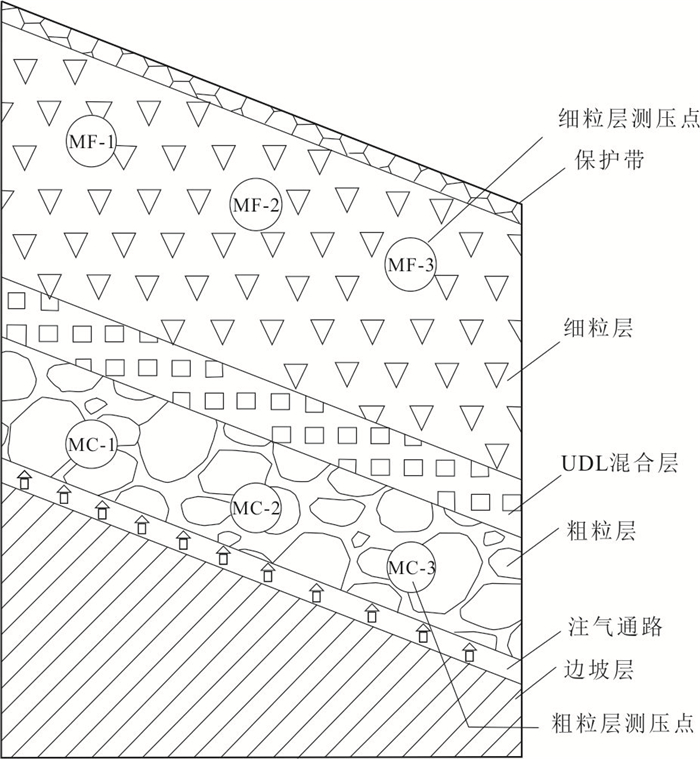
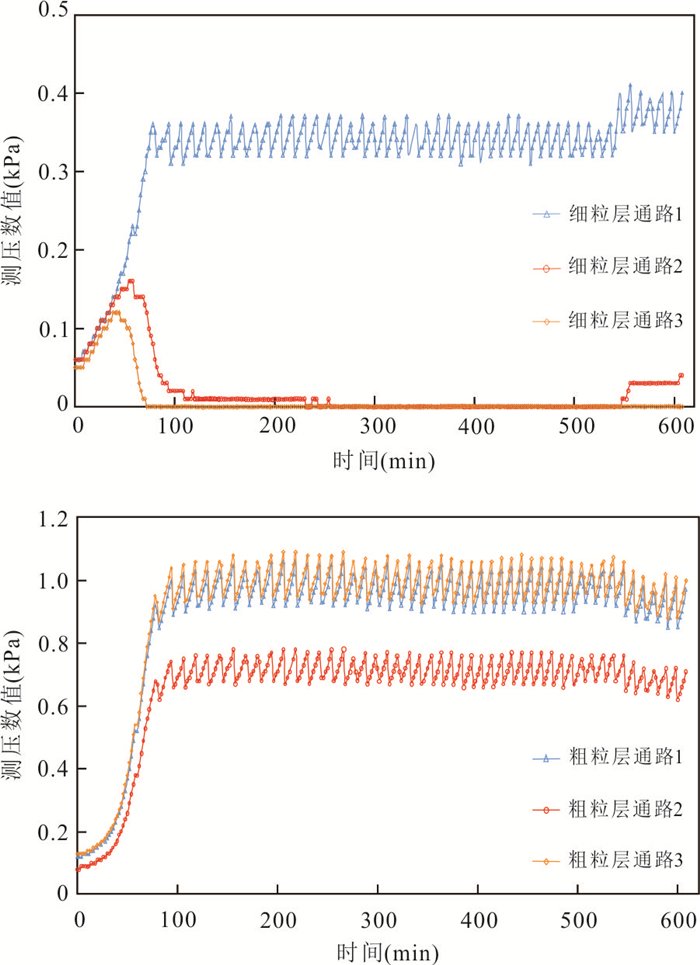
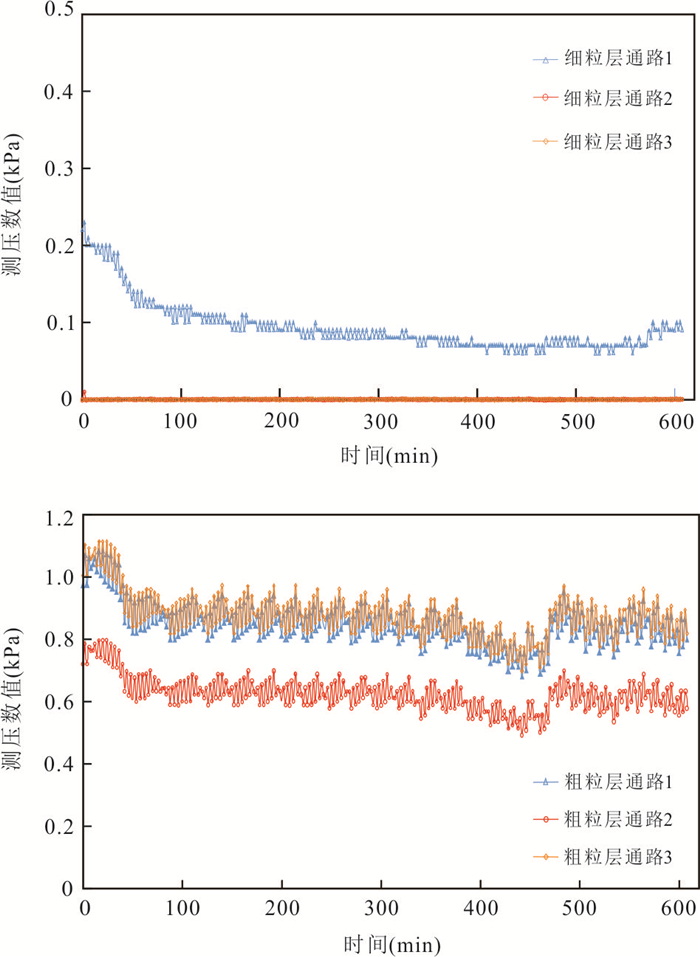
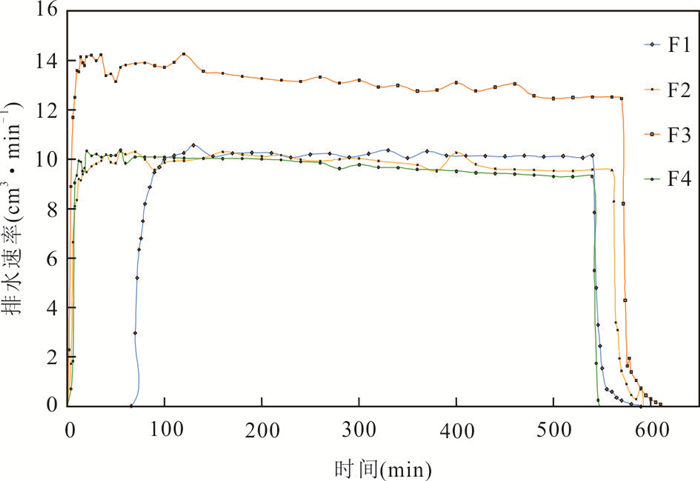
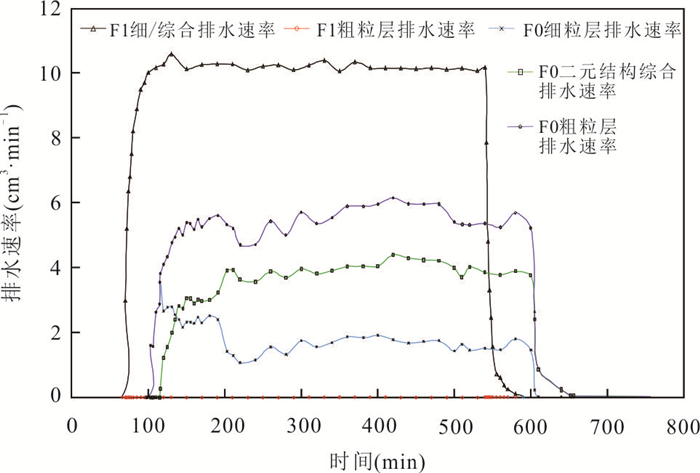
传统土质边坡表面硬化防渗措施易因降雨入渗产生干缩开裂问题,威胁工程安全,采用非饱和阻隔层(capillary barrier layer,CBL)阻隔保护可提升工程的长期稳定性,但存在导水能力随长期降雨入渗而下降的现象.针对传统非饱和阻隔层中毛细阻滞能力随降雨入渗衰减的问题,本文从水-气耦合角度,提出了通过粗粒层增压以增强非饱和阻隔层阻隔降雨入渗的方法.采用系列物理模型试验,在气密封闭条件下,探讨不同降雨强度、CBL初始含水量和粗粒层增压值等条件对其阻隔降雨入渗的影响,主要取得以下认知:(1)当粗粒层注气增压(1~3 kPa)时,降雨全部从细粒层、过渡层与粗粒层界面排出,完全抑制降雨突破过渡层/粗粒层界面而进入粗粒层,显著提升非饱和阻隔层的阻隔效率.(2)二元结构最大导排能力随粗粒层增压值增加而增大,而随细粒层含水量增加而下降.(3)提出综合阻隔性能指数以量化注气条件下非饱和阻隔层对降雨入渗的阻隔效果.该研究成果开创性地利用土体气相作为阻隔层排水驱动力,可为边坡防护工程等领域提供科学依据.



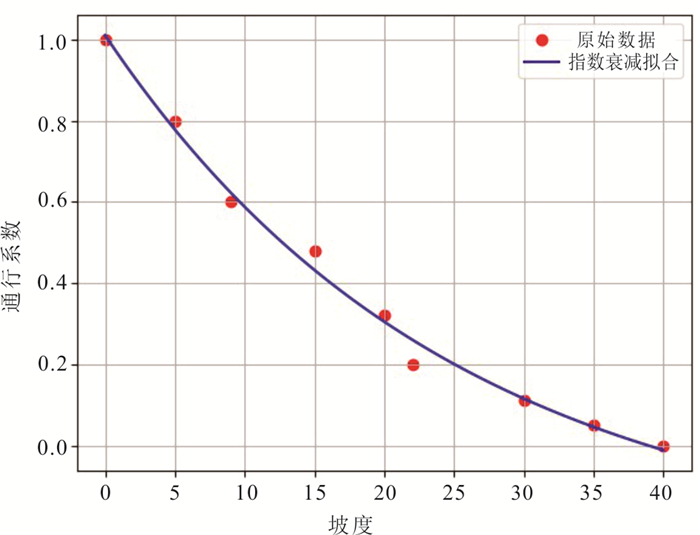
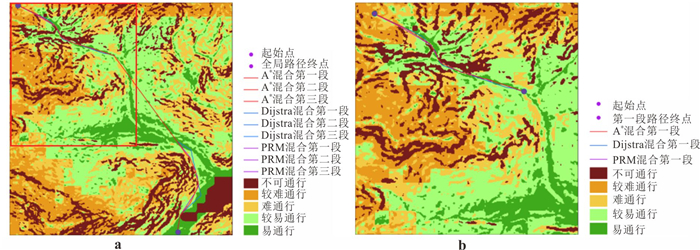
越野路径规划在应急救援等特殊场景任务中具有重要战略价值,但现有模型在复杂地形中存在通行性模型精度不足与求解效率低下的问题.为此,基于地质力学约束和融合土壤建模的思想,构建了通行性评估支撑的越野路径规划模型.首先,引入土壤湿度-硬度经验模型(SMSP Ⅱ)预测土壤额定圆锥系数(rating cone index,RCI),结合车辆额定圆锥指数(vehicle cone index,VCI),构建多要素约束且融合土壤通行性指标的通行度栅格图;在此基础上,提出一种融合分治策略与启发式搜索的改进NSGA-Ⅱ算法,并与Dijkstra算法集成,构建了多级混合路径优化框架.研究结果表明,论文提出的模型在路径可行性保持不变的前提下,计算效率提升约45%,路径通行度提升2%,路径长度缩短约2.1%.研究验证了论文提出的技术方法体系在复杂地质环境下越野路径规划的优越性能.



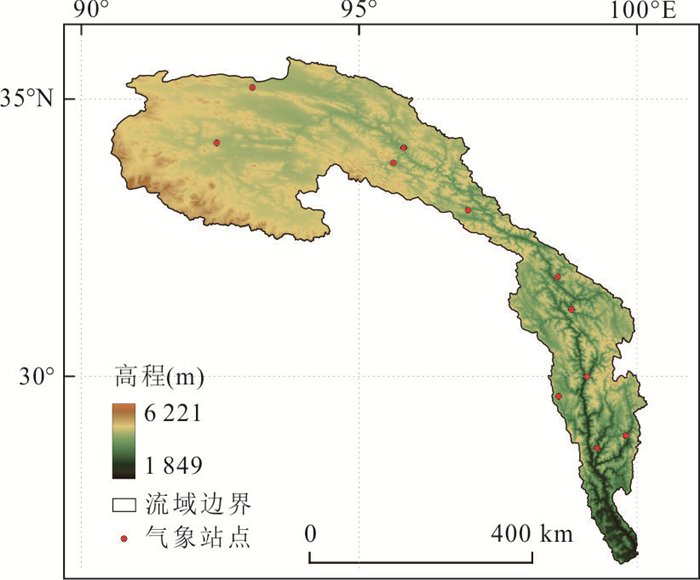
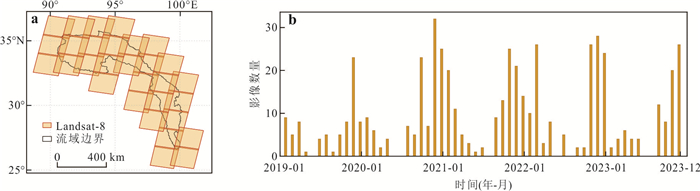
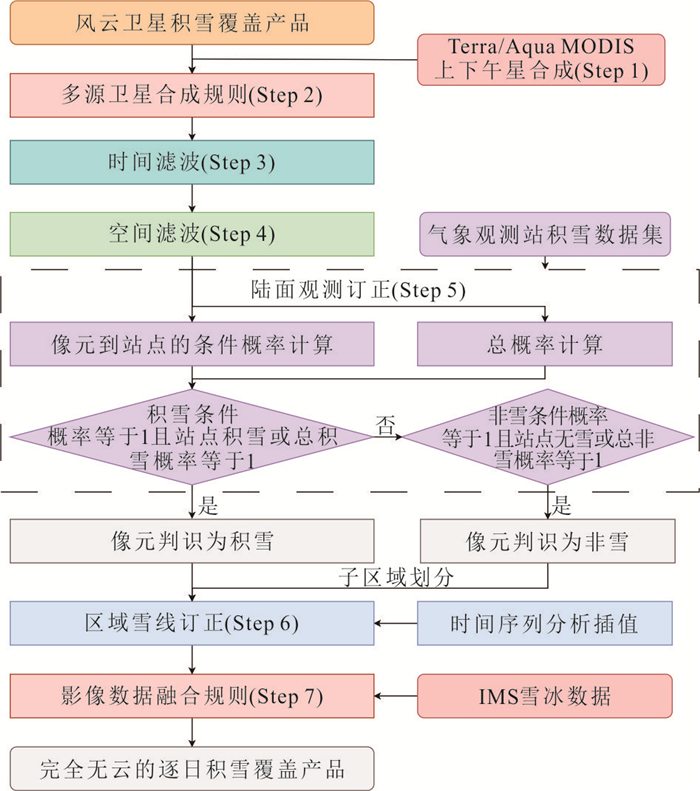
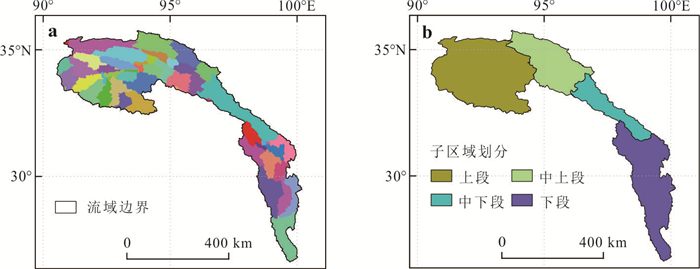
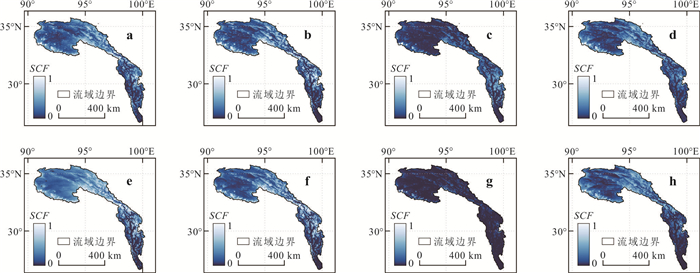
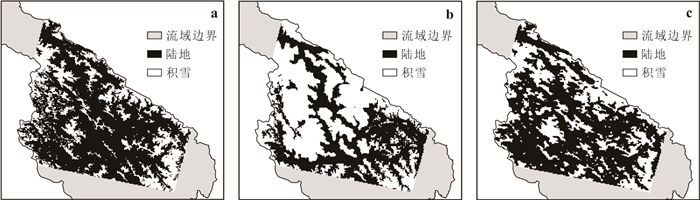
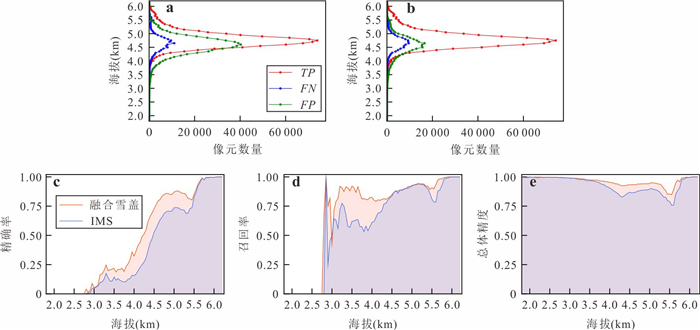
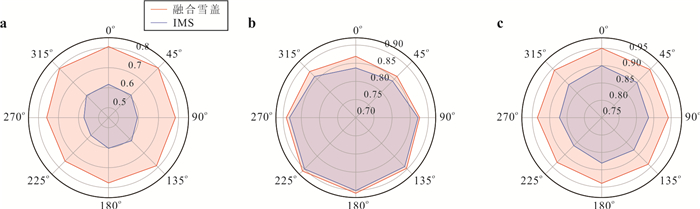
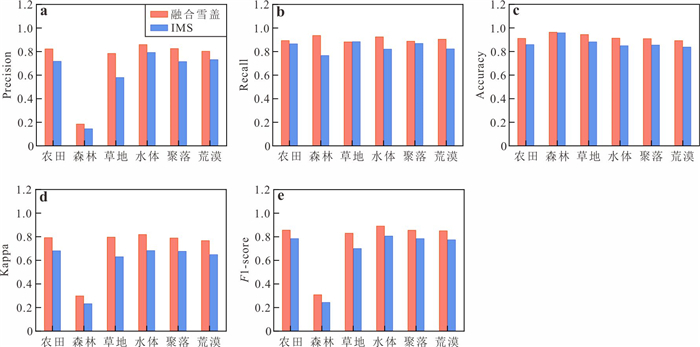
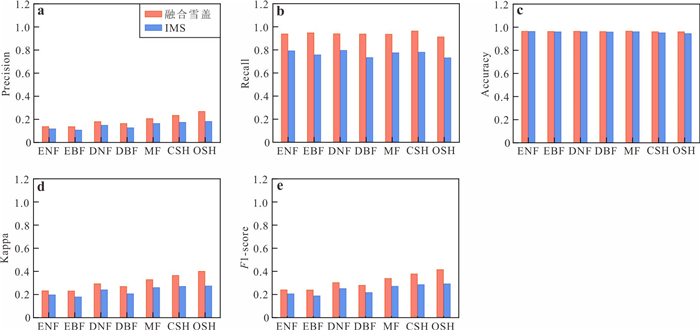
为了解决云层覆盖导致的积雪覆盖遥感监测产品数据缺失的问题,提出了一种基于风云卫星等多源数据融合的雪盖重建方法,通过7个去云步骤实现了金沙江上游高精度逐日无云雪盖监测.结果显示,融合后的雪盖产品总体精度能达到0.94,Kappa系数为0.80,比广泛使用的美国IMS雪冰产品的积雪监测效果更好.然而,融合雪盖产品的总体精度在海拔4.3 km和5.6 km左右有轻微下降,且产品精度随坡向的变化而出现差异.此外,融合雪盖产品在森林地区的精确率(0.18)远小于其他地区.未来在改进雪盖重建方法时,应考虑不同坡向的积雪分布以及森林地区的积雪特征,以提升多源融合无云雪盖产品的精度.


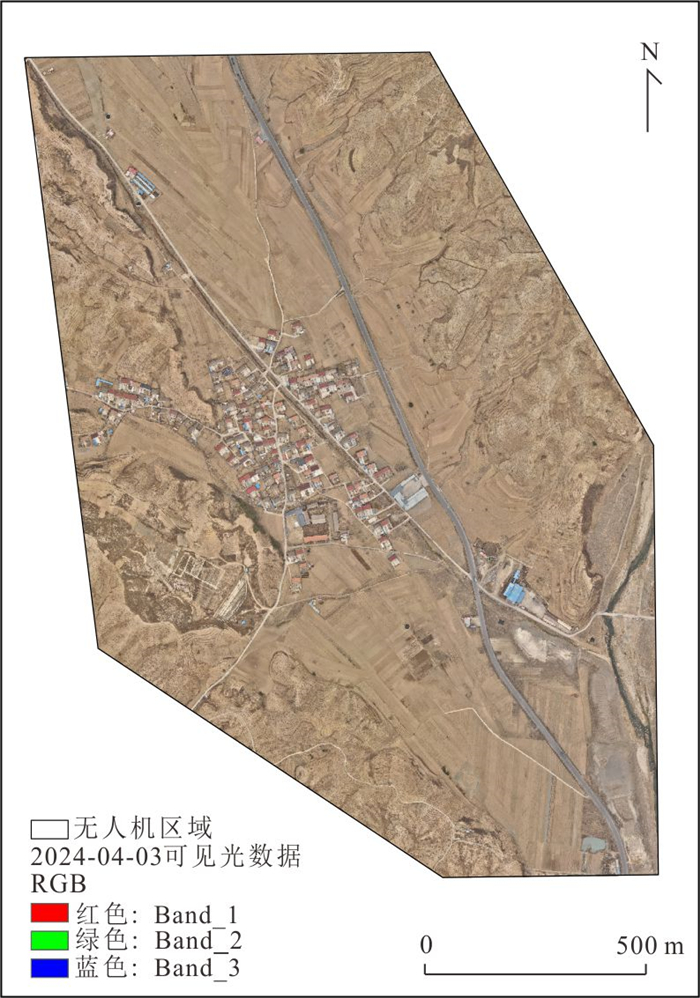
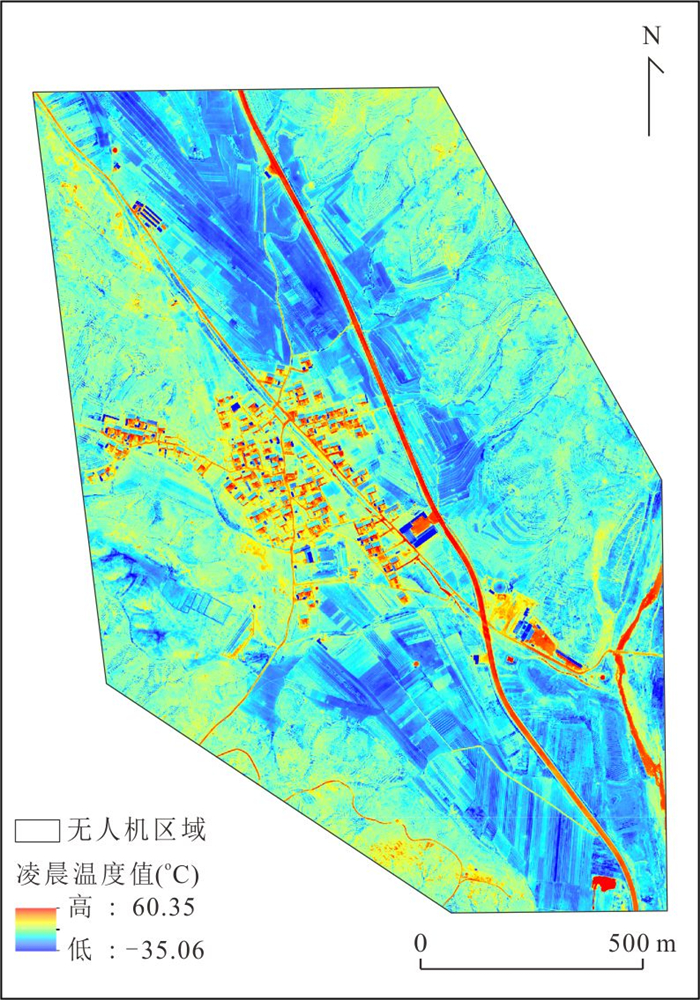
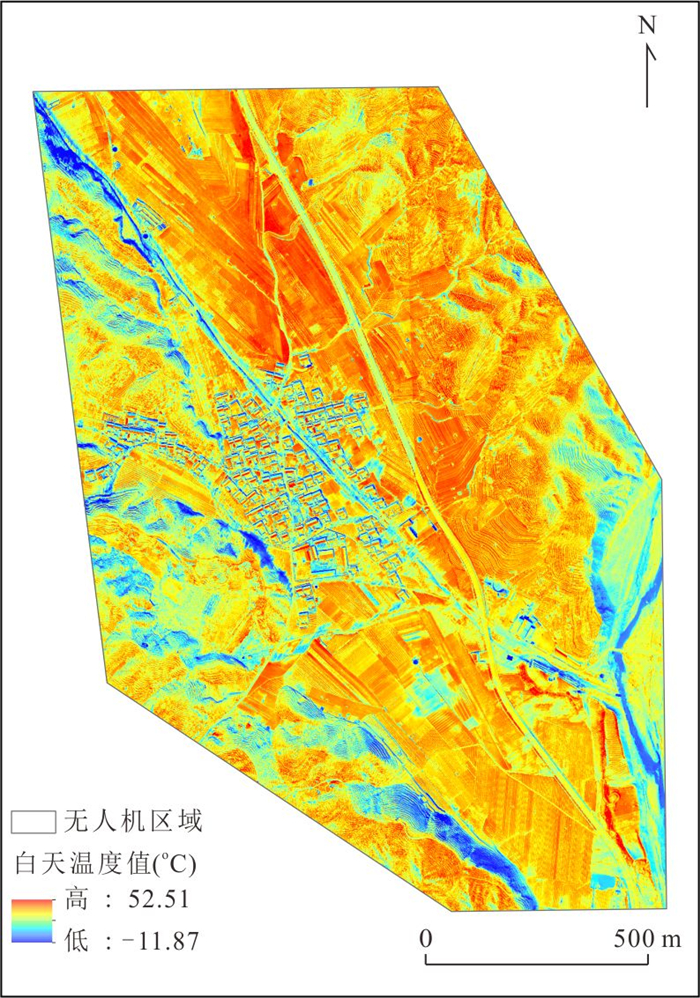
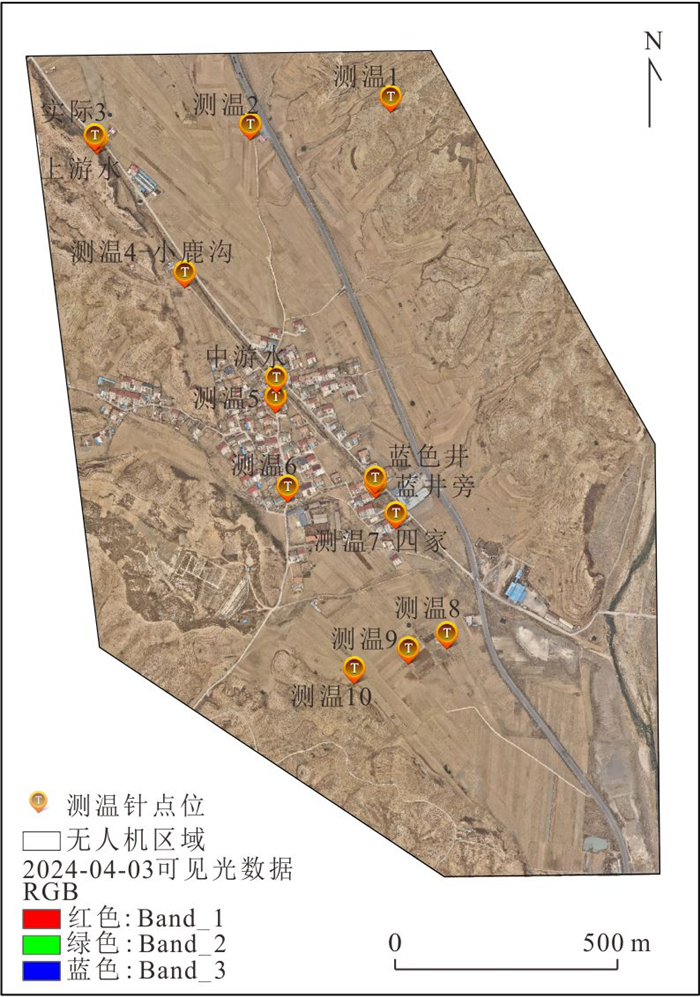
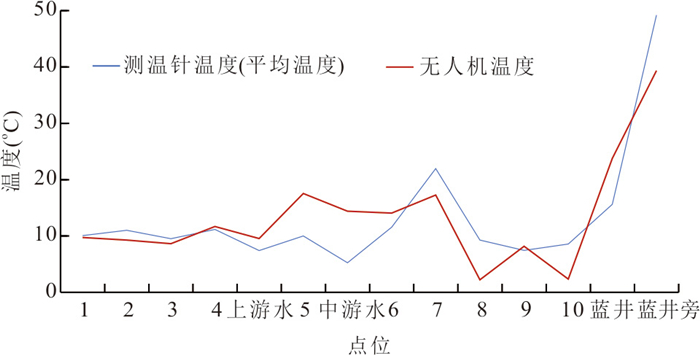
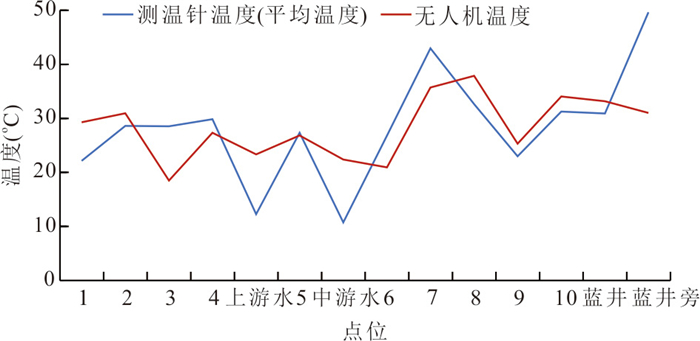
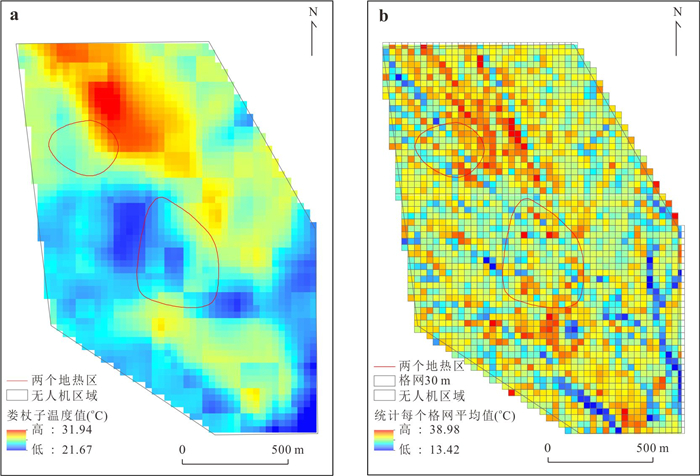
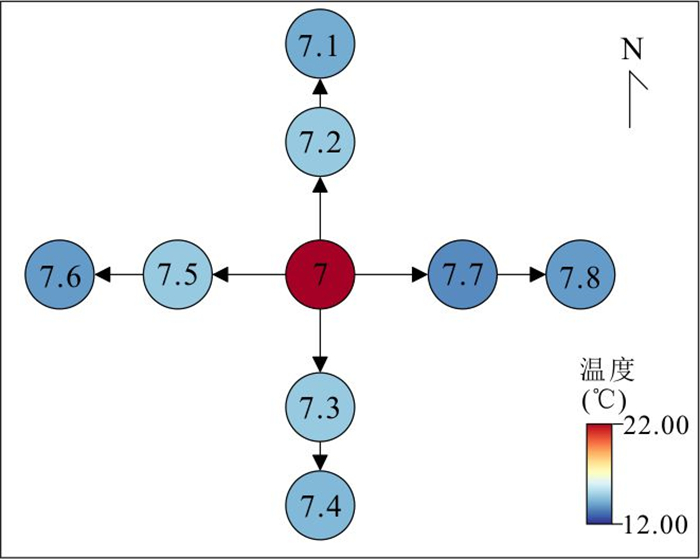
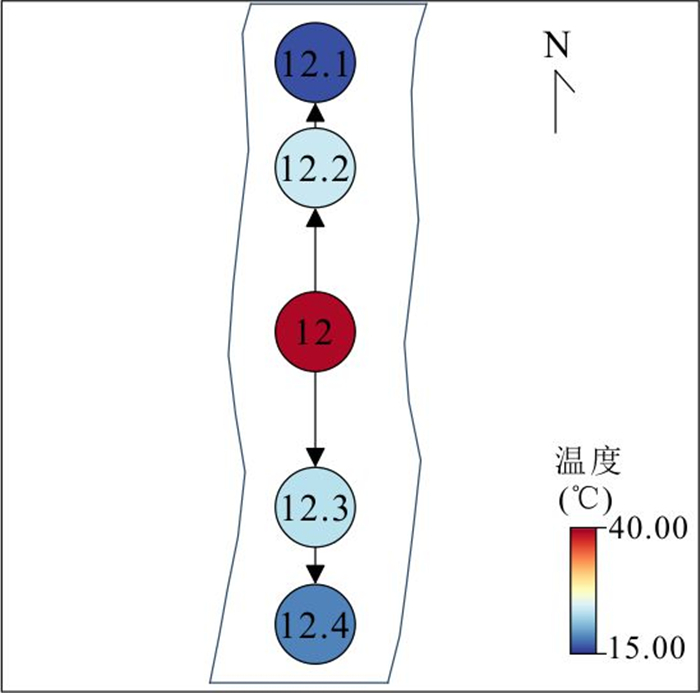
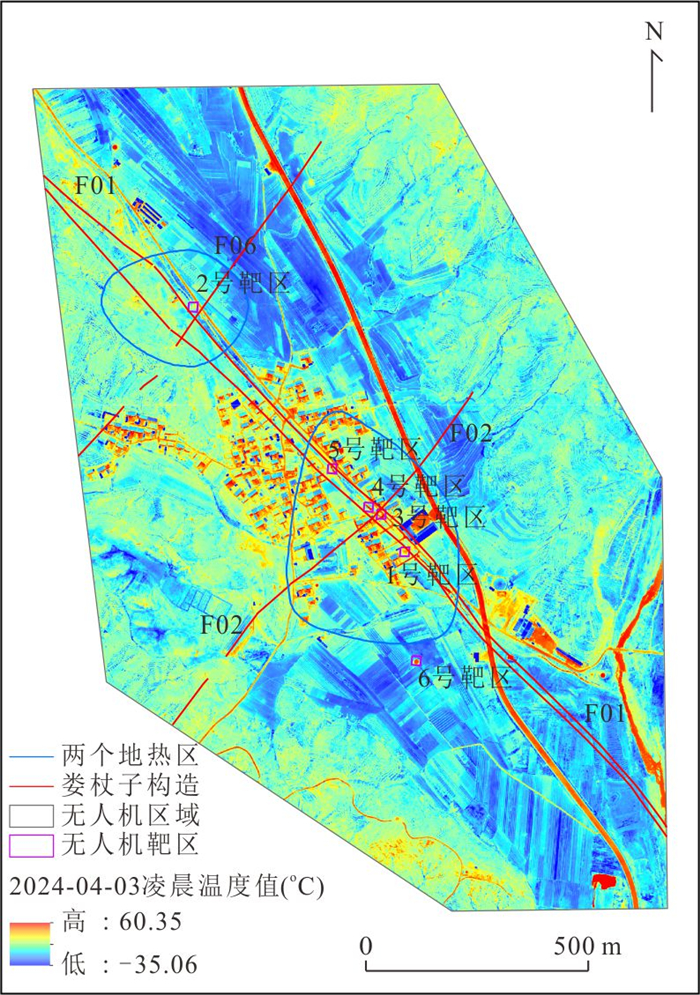
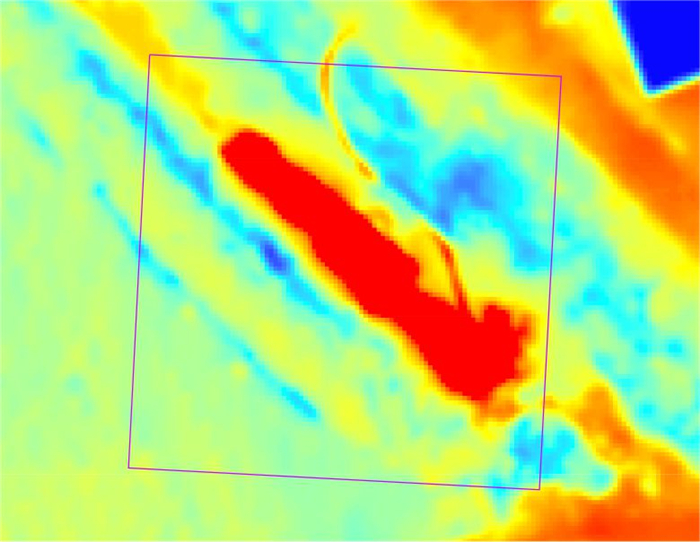
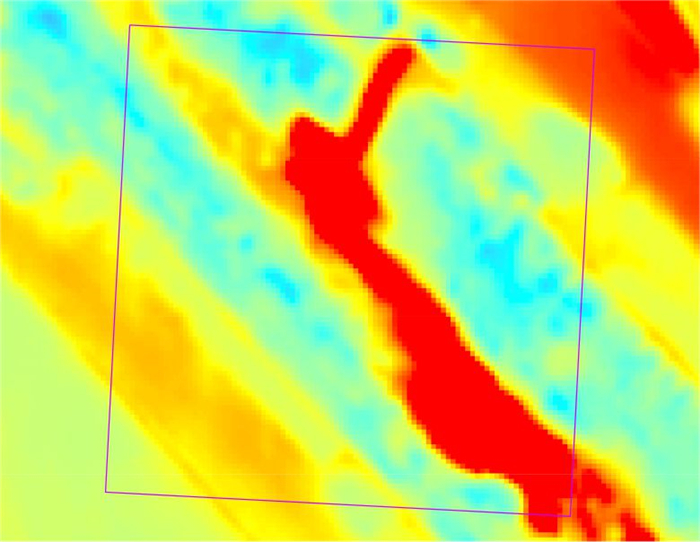
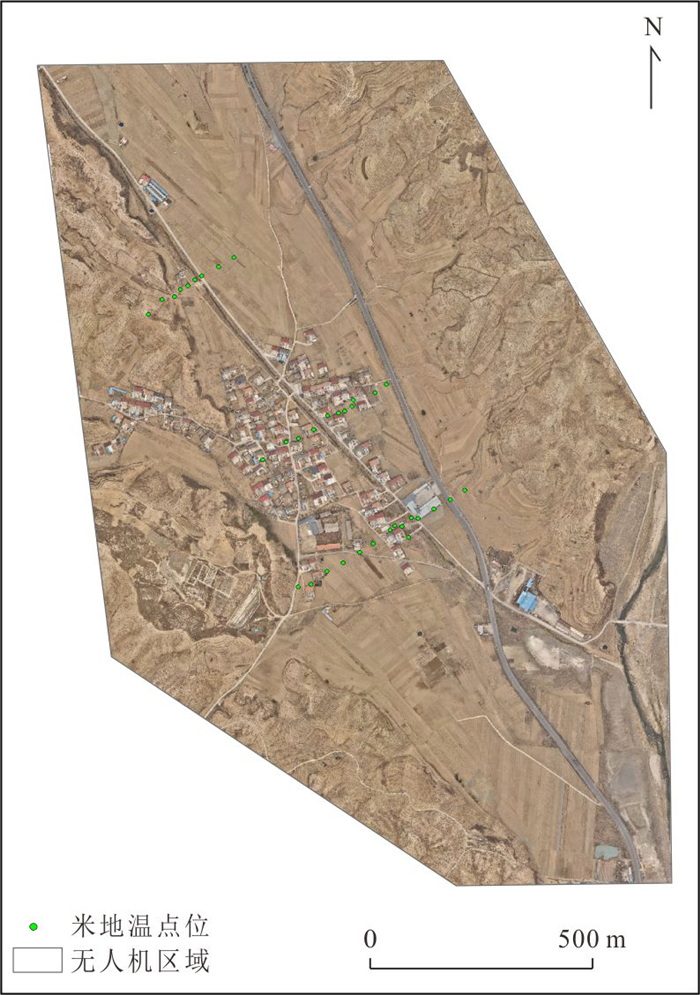
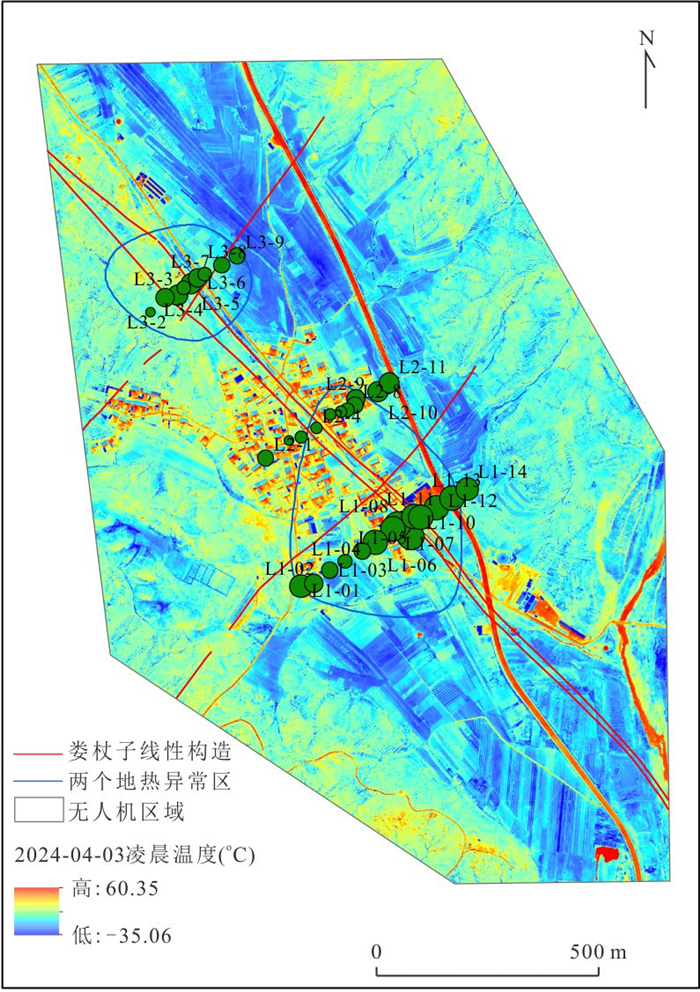
针对卫星热红外遥感在地热探测中存在空间分辨率低、易受太阳辐射影响等问题.研究依托DJI Mavic 3T无人机平台,获取研究区高分辨率真彩色与热红外影像.并基于DJI Thermal SDK建立自动化地表温度反演流程,得到无人机地表温度结果.通过现场温度实测数据验证,无人机温度结果与实测点位温度变化趋势具有良好一致性;将无人机热红外影像重采样至30 m后,与Landsat-8 TIRS温度反演结果在空间分布上有较强的一致性.基于提出的“十字型”与“一字型”地热靶区圈定模式,结合研究区构造格局与热异常分布规律,共识别出6处潜在地热靶区,并综合米地温实测数据与既有地质资料对其地热成因进行了分析.研究表明,无人机热红外技术能够在复杂山地环境中实现高精度地热异常识别,为小尺度地热靶区圈定、资源潜力评价提供重要技术支撑.未来需引入多深度米地温数据与浅层热扩散模型,以增强热异常与深部热源之间的定量联系.